Examples
Contents
This notebook demonstrates how to employ sforecast (sliding window) to fit an ML Model (out-of-sample train/test) and make predictions (future forecasts). Sforecast supports three model types - classical forecast models, SK learn models such as XGBoost, and Tensorflow.
For the case of SK Learn and TensorFlow, the models are defined externally to sforecast, and thus a reference to the model is passed into sforecast. For the classical forecasting models (ARIMA, SARIMAX, AUTOARIMA), the model parameters are passed into sforecast.
The notebook demonstrates examples for each of these model types and therein working with univariate and multivariate data, exogenous variables, endogenous variables, and categorical variables.
The scope of the notebook demonstrates the mechanics of setting up and running the corresponding data and models. Mathematical, statistical, and interpretation discussions are out of the scope.
Classical Forecasting Models
ARIMA
SARIMAX
Auto ARIMA
SK Learn ML Models
Superstore Data
Transforming to Wide Data Format
Univariate with XGBoost
Multivariate wit exogenous, endogenous, and multiple outputs
TensorFlow DL Models
M5 Walmart Sales Data, 7 Items
Univariate Deep Learning
Multivariate + Exogenous + Endogenous + Categorical Embeddings, Multiple Output
Several additional examples are included in the Github notebooks folder
Initialize Notebook
import sforecast as sf
print(f'sforecast version = {sf.__version__}')
import pandas as pd
import numpy as np
import beautifulplots as bp
import matplotlib.pyplot as plt
import matplotlib
from datetime import datetime
from pandas.plotting import autocorrelation_plot
datapath = "../data"
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
Cell In[1], line 1
----> 1 import sforecast as sf
2 print(f'sforecast version = {sf.__version__}')
3 import pandas as pd
ModuleNotFoundError: No module named 'sforecast'
1. Classical Models
ARIMA, Shampoo Sales
load data
# https://machinelearningmastery.com/arima-for-time-series-forecasting-with-python/ ... date parser and dataset
def dateparser(x):
return datetime.strptime('190'+x, '%Y-%m')
df_shampoo = pd.read_csv(f'{datapath}/shampoo.csv', parse_dates = ["Month"], date_parser=dateparser)
print("df_shampoo.shape =",df_shampoo.shape)
display(df_shampoo.head())
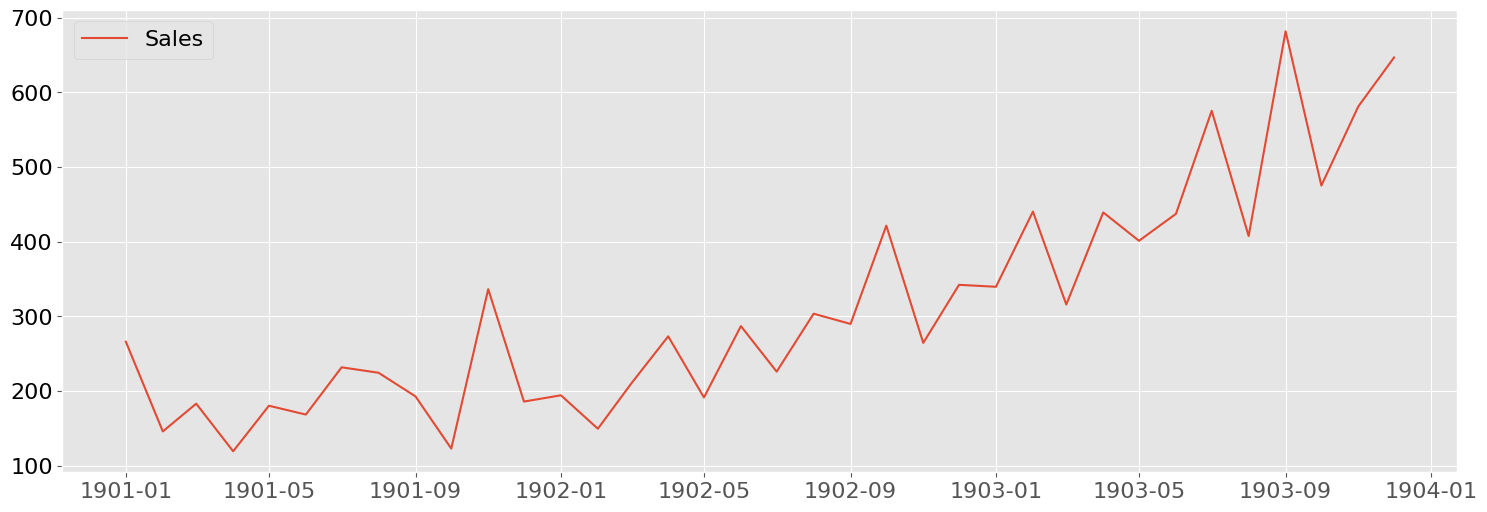
bp.lineplot(df_shampoo, x = "Month", y="Sales", figsize=(18,6), y_axis_format=".0f")
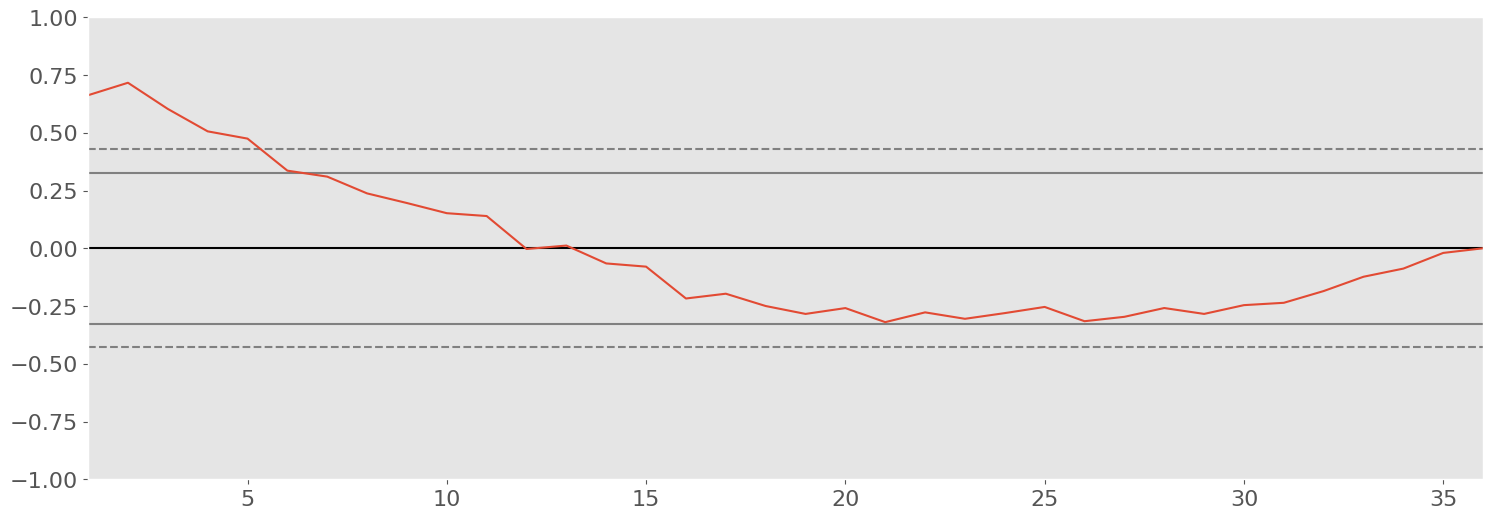
# Plot Sales Autocorrelation
fig,ax = plt.subplots(nrows=1, ncols=1,figsize=(18,6))
g=autocorrelation_plot(df_shampoo["Sales"])
plot_options = bp.plot_defaults()
bp.set_axisparams(plot_options,ax,g)
plt.show()
df_shampoo.shape = (36, 2)
/var/folders/mv/q8fjq_112p3cn5zntkpq1rjw0000gn/T/ipykernel_85989/3930567860.py:5: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
df_shampoo = pd.read_csv(f'{datapath}/shampoo.csv', parse_dates = ["Month"], date_parser=dateparser)
| Month | Sales | |
|---|---|---|
| 0 | 1901-01-01 | 266.0 |
| 1 | 1901-02-01 | 145.9 |
| 2 | 1901-03-01 | 183.1 |
| 3 | 1901-04-01 | 119.3 |
| 4 | 1901-05-01 | 180.3 |
Fit - ARIMA sliding 5 period forecast
Ntest = 5
y=["Sales"]
dfXY = df_shampoo[y]
print('dfXY')
display(dfXY.head())
swin_params = {
"Ntest":Ntest,
"Nlags": 5,
"minmax" :(0,None)}
cm_parameters = {
"model":"arima",
"order":(2,1,0)
}
sf_arima = sf.sliding_forecast (y = y,
model=None,
model_type="cm",
cm_parameters=cm_parameters,
swin_parameters=swin_params,)
df_pred_arima = sf_arima.fit(dfXY)
print(f'\nmetrics = {sf_arima.metrics}')
dfXY_pred_arima = df_shampoo.join(df_pred_arima)
display(dfXY_pred_arima.tail(Ntest))
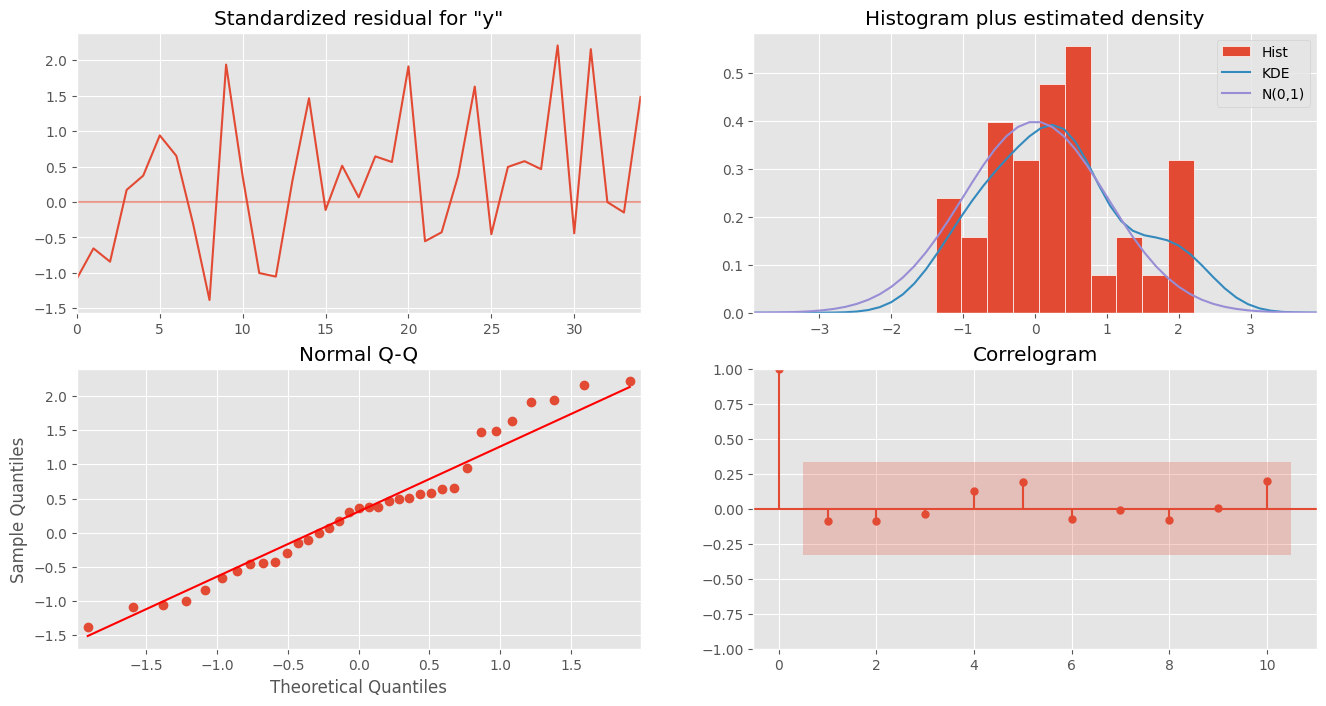
print(sf_arima.model_fit.summary())
sf_arima.model_fit.plot_diagnostics(figsize=(16, 8))
plt.show()
dfXY
| Sales | |
|---|---|
| 0 | 266.0 |
| 1 | 145.9 |
| 2 | 183.1 |
| 3 | 119.3 |
| 4 | 180.3 |
metrics = {'Sales_pred': {'RMSE': 96.4139361648774, 'MAE': 78.28000065334483}}
| Month | Sales | Sales_train | Sales_test | Sales_pred | Sales_pred_error | Sales_pred_lower | Sales_pred_upper | |
|---|---|---|---|---|---|---|---|---|
| 31 | 1903-08-01 | 407.6 | NaN | 407.6 | 467.811682 | 60.211682 | 321.109698 | 517.812587 |
| 32 | 1903-09-01 | 682.0 | NaN | 682.0 | 519.261277 | -162.738723 | 372.559293 | 569.262182 |
| 33 | 1903-10-01 | 475.3 | NaN | 475.3 | 464.182016 | -11.117984 | 317.480032 | 514.182921 |
| 34 | 1903-11-01 | 581.3 | NaN | 581.3 | 615.984739 | 34.684739 | 469.282755 | 665.985644 |
| 35 | 1903-12-01 | 646.9 | NaN | 646.9 | 524.253124 | -122.646876 | 377.551140 | 574.254029 |
SARIMAX Results
==============================================================================
Dep. Variable: y No. Observations: 36
Model: ARIMA(2, 1, 0) Log Likelihood -200.188
Date: Sat, 27 Jul 2024 AIC 406.376
Time: 08:28:21 BIC 411.042
Sample: 0 HQIC 407.987
- 36
Covariance Type: opg
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
ar.L1 -0.9139 0.225 -4.067 0.000 -1.354 -0.473
ar.L2 -0.2630 0.189 -1.392 0.164 -0.633 0.107
sigma2 5311.7175 1383.504 3.839 0.000 2600.099 8023.335
===================================================================================
Ljung-Box (L1) (Q): 0.29 Jarque-Bera (JB): 1.25
Prob(Q): 0.59 Prob(JB): 0.54
Heteroskedasticity (H): 1.48 Skew: 0.35
Prob(H) (two-sided): 0.51 Kurtosis: 2.39
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
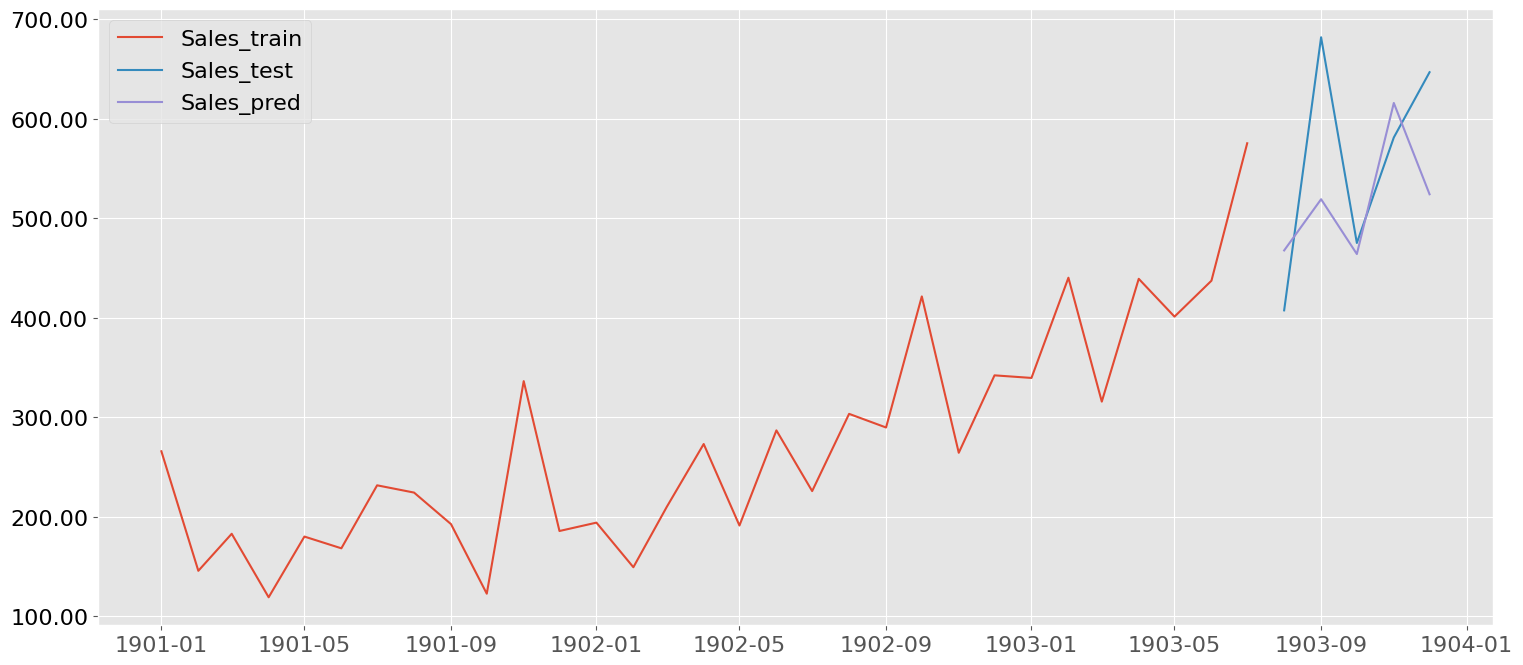
plot observations and predictions with beautifulplots.lineplot
ytrain = y[0]+"_train"
ytest = y[0]+"_test"
ypred = y[0]+"_pred"
error = y[0]+"_pred_error"
bp.lineplot(dfXY_pred_arima, x= "Month", y=[ytrain, ytest , ypred] , figsize=(18,8))
Predict - based on the previously fitted model
ts_period = pd.DateOffset(months=1)
df_pred=sf_arima.predict(Nperiods=1)
df_pred
| Sales_pred | |
|---|---|
| 36 | 559.074667 |
SARIMAX
load data
#data
#https://www.kaggle.com/datasets/rakannimer/air-passengers?resource=download
df_airp = pd.read_csv(f'{datapath}/AirPassengers.csv', parse_dates = ["Month"]).set_index("Month")
display(df_airp.head())
# rows with NA
print("rows with NA")
display(df_airp[df_airp.isna().any(axis=1)])
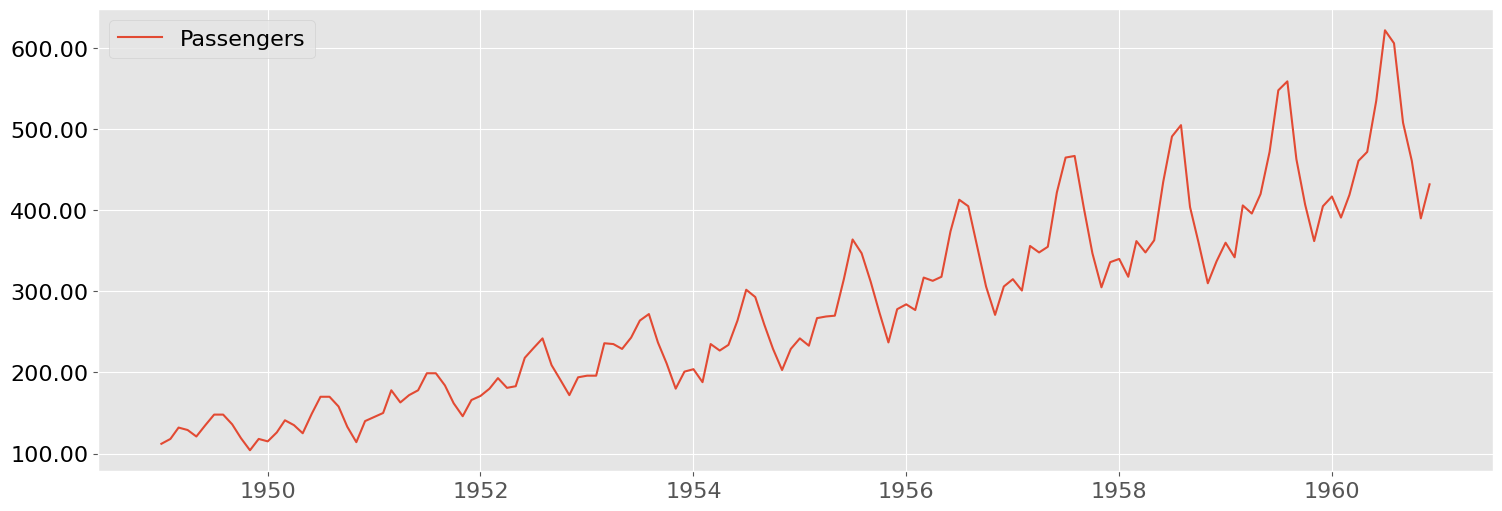
bp.lineplot(df_airp.reset_index(), x="Month", y=["Passengers"], figsize=(18,6))
| Passengers | |
|---|---|
| Month | |
| 1949-01-01 | 112 |
| 1949-02-01 | 118 |
| 1949-03-01 | 132 |
| 1949-04-01 | 129 |
| 1949-05-01 | 121 |
rows with NA
| Passengers | |
|---|---|
| Month |
Sarimax w/o exogenous or endogenous/derived variables
Ntest=5
dfXY = df_airp[["Passengers"]]
print('dfXY')
display(dfXY.head())
swin_parameters = {
"Ntest":Ntest,
"Nlags":5,
"minmax" :(0,None),
"Nhorizon":1,
}
cm_parameters = {
"model":"sarimax",
"order":(2,1,0),
"seasonal_order":(0,1,0,12)
}
y = "Passengers"
sf_sarimax = sf.sliding_forecast(y = y, model=None, model_type="cm", cm_parameters=cm_parameters,
swin_parameters=swin_parameters,)
df_pred_sarimax = sf_sarimax.fit(dfXY)
print(f'\nmetrics = {sf_sarimax.metrics}')
dfXY_pred_sarimax = dfXY.join(df_pred_sarimax)
display(dfXY_pred_sarimax.tail())
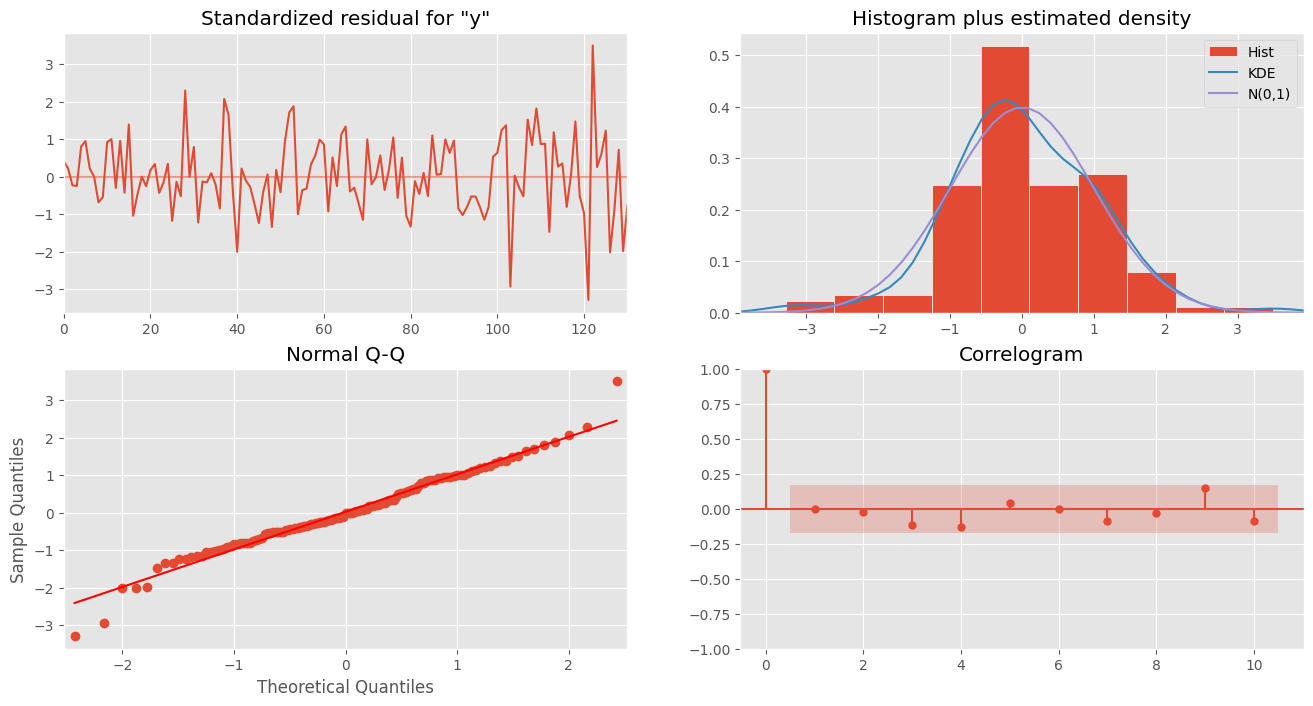
sf_sarimax.model_fit.plot_diagnostics(figsize=(16, 8))
plt.show()
dfXY
| Passengers | |
|---|---|
| Month | |
| 1949-01-01 | 112 |
| 1949-02-01 | 118 |
| 1949-03-01 | 132 |
| 1949-04-01 | 129 |
| 1949-05-01 | 121 |
metrics = {'Passengers_pred': {'RMSE': 16.743097882478537, 'MAE': 15.244803513154238}}
| Passengers | Passengers_train | Passengers_test | Passengers_pred | Passengers_pred_error | Passengers_pred_lower | Passengers_pred_upper | |
|---|---|---|---|---|---|---|---|
| Month | |||||||
| 1960-08-01 | 606 | NaN | 606.0 | 630.137901 | 24.137901 | 628.589746 | 653.908643 |
| 1960-09-01 | 508 | NaN | 508.0 | 518.765675 | 10.765675 | 517.217519 | 542.536416 |
| 1960-10-01 | 461 | NaN | 461.0 | 452.211668 | -8.788332 | 450.663512 | 475.982410 |
| 1960-11-01 | 390 | NaN | 390.0 | 413.220001 | 23.220001 | 411.671846 | 436.990743 |
| 1960-12-01 | 432 | NaN | 432.0 | 441.312108 | 9.312108 | 439.763953 | 465.082850 |
Predict Sarimax no exogs
ts_period = pd.DateOffset(months=1)
df_pred=sf_sarimax.predict(Nperiods=1,ts_period=ts_period)
df_pred
| Passengers_pred | |
|---|---|
| 1961-01-01 | 444.327801 |
Exogenous Variables
These variables are not dependent and are ususally some form of external varialbe. For example, they could represent the weather, such as temperature or rain, or economic data, such as consumer confience index.
The variables are included in the input dataframe to the fit operation. An exogenous variables dataframe, one row per predict period (i.e., index), is input to the predict operation.
Below is trivial example of exogenous variables, the month number is included as an exogenous variable input. df_airp has two variables the target variable and y = Passengers, and exogenous variable month_no
# add exogenous variable "month_no"
# df_airp has two variables the target variable y = Passengers,
# and exogenous variable month_no
dfXY = df_airp.copy()
# Exogenous variables
dfXY["month_no"] = dfXY.index.month # exog variable
display(dfXY)
| Passengers | month_no | |
|---|---|---|
| Month | ||
| 1949-01-01 | 112 | 1 |
| 1949-02-01 | 118 | 2 |
| 1949-03-01 | 132 | 3 |
| 1949-04-01 | 129 | 4 |
| 1949-05-01 | 121 | 5 |
| ... | ... | ... |
| 1960-08-01 | 606 | 8 |
| 1960-09-01 | 508 | 9 |
| 1960-10-01 | 461 | 10 |
| 1960-11-01 | 390 | 11 |
| 1960-12-01 | 432 | 12 |
144 rows × 2 columns
Saramax w/ Exogs
Ntest = 3
display(dfXY.head())
exogvars = ["month_no"]
swin_parameters = {
"Ntest":Ntest,
"Nlags":5,
"minmax" :(0,None),
"Nhorizon":1,
"exogvars": exogvars
}
cm_parameters = {
"model":"sarimax",
"order":(2,1,0),
"seasonal_order":(0,1,0,12)
}
y = "Passengers"
sf_sarimax = sf.sliding_forecast(y = y, model=None, model_type="cm", cm_parameters=cm_parameters,
swin_parameters=swin_parameters,)
df_pred_sarimax = sf_sarimax.fit(dfXY)
print(f'\nmetrics = {sf_sarimax.metrics}')
dfXY_pred_sarimax = dfXY.join(df_pred_sarimax)
display(dfXY_pred_sarimax.tail())
sf_sarimax.model_fit.plot_diagnostics(figsize=(16, 8))
plt.show()
| Passengers | month_no | |
|---|---|---|
| Month | ||
| 1949-01-01 | 112 | 1 |
| 1949-02-01 | 118 | 2 |
| 1949-03-01 | 132 | 3 |
| 1949-04-01 | 129 | 4 |
| 1949-05-01 | 121 | 5 |
metrics = {'Passengers_pred': {'RMSE': 15.309241439681522, 'MAE': 13.773480924095225}}
| Passengers | month_no | Passengers_train | Passengers_test | Passengers_pred | Passengers_pred_error | Passengers_pred_lower | Passengers_pred_upper | |
|---|---|---|---|---|---|---|---|---|
| Month | ||||||||
| 1960-08-01 | 606 | 8 | 606.0 | NaN | NaN | NaN | NaN | NaN |
| 1960-09-01 | 508 | 9 | 508.0 | NaN | NaN | NaN | NaN | NaN |
| 1960-10-01 | 461 | 10 | NaN | 461.0 | 452.211667 | -8.788333 | 447.043422 | 472.650089 |
| 1960-11-01 | 390 | 11 | NaN | 390.0 | 413.220001 | 23.220001 | 408.051756 | 433.658424 |
| 1960-12-01 | 432 | 12 | NaN | 432.0 | 441.312108 | 9.312108 | 436.143863 | 461.750531 |
predict sarimax w/ exogs
ts_period = pd.DateOffset(months=1)
dfexogs = pd.DataFrame(data={"month_no":[1]})
df_pred=sf_sarimax.predict(Nperiods=1,dfexogs = dfexogs, ts_period=ts_period)
df_pred
| Passengers_pred | |
|---|---|
| 1961-01-01 | 444.327802 |
Auto ARIMA
exenvars = None … without exogvars and without derived attributes
Ntest = 4
Nhorizon = 2
dfXY = df_airp
print("dfXY.index.size = ", dfXY.index.size)
print('dfXY.tail()')
display(dfXY.tail())
swin_params = {
"Ntest":Ntest,
"Nlags":5,
"Nhorizon": Nhorizon,
"minmax" :(0,None)
}
cm_parameters = {
"model":"auto_arima",
"d":None, # let the auto search determine d
"start_p":1,
"start_q":1,
"seasonal":True ,
"D":None, # let auto search determine D
"m":12, # 12, period (i.e., month) seasonality period
"start_P":1,
"start_Q":1,
"error_action":"ignore", # don't want to know if order does not work
"suppress_warnings":True, # don't want convergence warnings
"stepwise":True # stepwise search
}
y = "Passengers"
sf_autoarima = sf.sliding_forecast(y = y, model=None, model_type="cm", cm_parameters=cm_parameters,
swin_parameters=swin_params,)
df_pred_autoarima = sf_autoarima.fit(dfXY)
print(f'\nmetrics = {sf_autoarima.metrics}')
print("confidence intervals = ",sf_autoarima.ci )
dfXY_pred_autoarima = dfXY.join(df_pred_autoarima)
display(dfXY_pred_autoarima.tail())
dfXY.index.size = 144
dfXY.tail()
| Passengers | |
|---|---|
| Month | |
| 1960-08-01 | 606 |
| 1960-09-01 | 508 |
| 1960-10-01 | 461 |
| 1960-11-01 | 390 |
| 1960-12-01 | 432 |
Performing stepwise search to minimize aic
ARIMA(1,1,1)(1,1,1)[12] : AIC=inf, Time=0.79 sec
ARIMA(0,1,0)(0,1,0)[12] : AIC=999.041, Time=0.01 sec
ARIMA(1,1,0)(1,1,0)[12] : AIC=988.030, Time=0.05 sec
ARIMA(0,1,1)(0,1,1)[12] : AIC=988.606, Time=0.09 sec
ARIMA(1,1,0)(0,1,0)[12] : AIC=987.497, Time=0.02 sec
ARIMA(1,1,0)(0,1,1)[12] : AIC=988.367, Time=0.07 sec
ARIMA(1,1,0)(1,1,1)[12] : AIC=inf, Time=0.22 sec
ARIMA(2,1,0)(0,1,0)[12] : AIC=989.465, Time=0.03 sec
ARIMA(1,1,1)(0,1,0)[12] : AIC=989.427, Time=0.03 sec
ARIMA(0,1,1)(0,1,0)[12] : AIC=987.923, Time=0.02 sec
ARIMA(2,1,1)(0,1,0)[12] : AIC=985.987, Time=0.10 sec
ARIMA(2,1,1)(1,1,0)[12] : AIC=986.643, Time=0.30 sec
ARIMA(2,1,1)(0,1,1)[12] : AIC=986.912, Time=0.30 sec
ARIMA(2,1,1)(1,1,1)[12] : AIC=inf, Time=0.40 sec
ARIMA(3,1,1)(0,1,0)[12] : AIC=986.774, Time=0.16 sec
ARIMA(2,1,2)(0,1,0)[12] : AIC=987.058, Time=0.10 sec
ARIMA(1,1,2)(0,1,0)[12] : AIC=991.196, Time=0.07 sec
ARIMA(3,1,0)(0,1,0)[12] : AIC=989.977, Time=0.04 sec
ARIMA(3,1,2)(0,1,0)[12] : AIC=988.749, Time=0.20 sec
ARIMA(2,1,1)(0,1,0)[12] intercept : AIC=inf, Time=0.27 sec
Best model: ARIMA(2,1,1)(0,1,0)[12]
Total fit time: 3.310 seconds
Performing stepwise search to minimize aic
ARIMA(1,1,1)(1,1,1)[12] : AIC=inf, Time=0.64 sec
ARIMA(0,1,0)(0,1,0)[12] : AIC=1013.300, Time=0.01 sec
ARIMA(1,1,0)(1,1,0)[12] : AIC=1002.581, Time=0.05 sec
ARIMA(0,1,1)(0,1,1)[12] : AIC=1002.865, Time=0.08 sec
ARIMA(1,1,0)(0,1,0)[12] : AIC=1002.322, Time=0.02 sec
ARIMA(1,1,0)(0,1,1)[12] : AIC=1003.021, Time=0.07 sec
ARIMA(1,1,0)(1,1,1)[12] : AIC=1002.057, Time=0.19 sec
ARIMA(1,1,0)(2,1,1)[12] : AIC=inf, Time=1.54 sec
ARIMA(1,1,0)(1,1,2)[12] : AIC=1003.949, Time=0.45 sec
ARIMA(1,1,0)(0,1,2)[12] : AIC=1001.970, Time=0.39 sec
ARIMA(1,1,0)(0,1,3)[12] : AIC=1003.965, Time=0.54 sec
ARIMA(1,1,0)(1,1,3)[12] : AIC=inf, Time=2.49 sec
ARIMA(0,1,0)(0,1,2)[12] : AIC=1014.321, Time=0.21 sec
ARIMA(2,1,0)(0,1,2)[12] : AIC=1003.920, Time=0.34 sec
ARIMA(1,1,1)(0,1,2)[12] : AIC=1003.836, Time=0.60 sec
ARIMA(0,1,1)(0,1,2)[12] : AIC=1001.850, Time=0.32 sec
ARIMA(0,1,1)(1,1,2)[12] : AIC=1003.850, Time=0.39 sec
ARIMA(0,1,1)(0,1,3)[12] : AIC=1003.850, Time=0.65 sec
ARIMA(0,1,1)(1,1,1)[12] : AIC=inf, Time=0.41 sec
ARIMA(0,1,1)(1,1,3)[12] : AIC=inf, Time=2.98 sec
ARIMA(0,1,2)(0,1,2)[12] : AIC=1003.850, Time=0.36 sec
ARIMA(1,1,2)(0,1,2)[12] : AIC=1005.463, Time=0.60 sec
ARIMA(0,1,1)(0,1,2)[12] intercept : AIC=1003.458, Time=0.50 sec
Best model: ARIMA(0,1,1)(0,1,2)[12]
Total fit time: 13.873 seconds
Performing stepwise search to minimize aic
ARIMA(1,1,1)(1,1,1)[12] : AIC=1022.299, Time=0.37 sec
ARIMA(0,1,0)(0,1,0)[12] : AIC=1031.508, Time=0.01 sec
ARIMA(1,1,0)(1,1,0)[12] : AIC=1020.393, Time=0.07 sec
ARIMA(0,1,1)(0,1,1)[12] : AIC=1021.003, Time=0.10 sec
ARIMA(1,1,0)(0,1,0)[12] : AIC=1020.393, Time=0.03 sec
ARIMA(1,1,0)(2,1,0)[12] : AIC=1019.239, Time=0.18 sec
ARIMA(1,1,0)(2,1,1)[12] : AIC=inf, Time=1.56 sec
ARIMA(1,1,0)(1,1,1)[12] : AIC=1020.493, Time=0.22 sec
ARIMA(0,1,0)(2,1,0)[12] : AIC=1032.120, Time=0.13 sec
ARIMA(2,1,0)(2,1,0)[12] : AIC=1021.120, Time=0.28 sec
ARIMA(1,1,1)(2,1,0)[12] : AIC=1021.032, Time=0.33 sec
ARIMA(0,1,1)(2,1,0)[12] : AIC=1019.178, Time=0.19 sec
ARIMA(0,1,1)(1,1,0)[12] : AIC=1020.425, Time=0.07 sec
ARIMA(0,1,1)(2,1,1)[12] : AIC=inf, Time=1.05 sec
ARIMA(0,1,1)(1,1,1)[12] : AIC=1020.327, Time=0.31 sec
ARIMA(0,1,2)(2,1,0)[12] : AIC=1021.148, Time=0.25 sec
ARIMA(1,1,2)(2,1,0)[12] : AIC=1022.805, Time=0.38 sec
ARIMA(0,1,1)(2,1,0)[12] intercept : AIC=1021.017, Time=0.35 sec
Best model: ARIMA(0,1,1)(2,1,0)[12]
Total fit time: 5.971 seconds
metrics = {'Passengers_pred': {'RMSE': 16.037522157164187, 'MAE': 13.985532763912914}}
confidence intervals = {'Passengers': [(8.288830543281938, 21.078151954564554), (-2.991575951134382, 18.26854289510975)]}
| Passengers | Passengers_train | Passengers_test | Passengers_pred | Passengers_pred_error | Passengers_pred_lower | Passengers_pred_upper | |
|---|---|---|---|---|---|---|---|
| Month | |||||||
| 1960-08-01 | 606 | 606.0 | NaN | NaN | NaN | NaN | NaN |
| 1960-09-01 | 508 | NaN | 508.0 | 514.690165 | 6.690165 | 522.978996 | 535.768317 |
| 1960-10-01 | 461 | NaN | 461.0 | 455.350909 | -5.649091 | 452.359333 | 473.619452 |
| 1960-11-01 | 390 | NaN | 390.0 | 412.676817 | 22.676817 | 420.965648 | 433.754969 |
| 1960-12-01 | 432 | NaN | 432.0 | 452.926058 | 20.926058 | 449.934482 | 471.194601 |
predict autoarima
ts_period = pd.DateOffset(months=1)
df_pred=sf_autoarima.predict(Nperiods=3, ts_period=ts_period)
df_pred
| Passengers_pred | |
|---|---|
| 1961-01-01 | 451.347077 |
| 1961-02-01 | 427.102222 |
| 1961-03-01 | 463.382490 |
Auto Arima with Exogenous Variables
Ntest = 3
Nhorizon = 3
dfXY = df_airp.copy()
# Exogenous variables
dfXY["month_no"] = dfXY.index.month # exog variable
print('dfXY')
display(dfXY.head())
exogvars = ["month_no"]
swin_params = {
"Ntest":Ntest,
"Nlags":5,
"Nhorizon":Nhorizon,
"minmax" :(0,None),
"exogvars": exogvars,
}
cm_parameters = {
"model":"auto_arima",
"d":None, # let the auto search determine d
"start_p":1,
"start_q":1,
"seasonal":True ,
"D":None, # let auto search determine D
"m":12, # 12, period (i.e., month) seasonality period
"start_P":1,
"start_Q":1,
"error_action":"ignore", # don't want to know if order does not work
"suppress_warnings":True, # don't want convergence warnings
"stepwise":True # stepwise search
}
y = "Passengers"
sf_autoarima = sf.sliding_forecast(y = y, model=None, model_type="cm", cm_parameters=cm_parameters,
swin_parameters=swin_params,)
df_pred_autoarima = sf_autoarima.fit(dfXY)
print(f'\nmetrics = {sf_autoarima.metrics}')
dfXY_pred_autoarima = dfXY.join(df_pred_autoarima)
display(dfXY_pred_autoarima.tail())
dfXY
| Passengers | month_no | |
|---|---|---|
| Month | ||
| 1949-01-01 | 112 | 1 |
| 1949-02-01 | 118 | 2 |
| 1949-03-01 | 132 | 3 |
| 1949-04-01 | 129 | 4 |
| 1949-05-01 | 121 | 5 |
Performing stepwise search to minimize aic
ARIMA(1,1,1)(1,1,1)[12] : AIC=inf, Time=0.87 sec
ARIMA(0,1,0)(0,1,0)[12] : AIC=1005.914, Time=0.01 sec
ARIMA(1,1,0)(1,1,0)[12] : AIC=995.467, Time=0.06 sec
ARIMA(0,1,1)(0,1,1)[12] : AIC=995.933, Time=0.09 sec
ARIMA(1,1,0)(0,1,0)[12] : AIC=995.060, Time=0.02 sec
ARIMA(1,1,0)(0,1,1)[12] : AIC=995.871, Time=0.08 sec
ARIMA(1,1,0)(1,1,1)[12] : AIC=inf, Time=0.27 sec
ARIMA(2,1,0)(0,1,0)[12] : AIC=997.033, Time=0.04 sec
ARIMA(1,1,1)(0,1,0)[12] : AIC=996.991, Time=0.05 sec
ARIMA(0,1,1)(0,1,0)[12] : AIC=995.306, Time=0.02 sec
ARIMA(2,1,1)(0,1,0)[12] : AIC=993.005, Time=0.14 sec
ARIMA(2,1,1)(1,1,0)[12] : AIC=993.546, Time=0.41 sec
ARIMA(2,1,1)(0,1,1)[12] : AIC=993.857, Time=0.41 sec
ARIMA(2,1,1)(1,1,1)[12] : AIC=inf, Time=0.50 sec
ARIMA(3,1,1)(0,1,0)[12] : AIC=993.754, Time=0.16 sec
ARIMA(2,1,2)(0,1,0)[12] : AIC=994.037, Time=0.16 sec
ARIMA(1,1,2)(0,1,0)[12] : AIC=998.702, Time=0.06 sec
ARIMA(3,1,0)(0,1,0)[12] : AIC=997.294, Time=0.04 sec
ARIMA(3,1,2)(0,1,0)[12] : AIC=995.720, Time=0.34 sec
ARIMA(2,1,1)(0,1,0)[12] intercept : AIC=inf, Time=0.32 sec
Best model: ARIMA(2,1,1)(0,1,0)[12]
Total fit time: 4.105 seconds
Performing stepwise search to minimize aic
ARIMA(1,1,1)(1,1,1)[12] : AIC=1022.299, Time=0.36 sec
ARIMA(0,1,0)(0,1,0)[12] : AIC=1031.508, Time=0.01 sec
ARIMA(1,1,0)(1,1,0)[12] : AIC=1020.393, Time=0.06 sec
ARIMA(0,1,1)(0,1,1)[12] : AIC=1021.003, Time=0.09 sec
ARIMA(1,1,0)(0,1,0)[12] : AIC=1020.393, Time=0.02 sec
ARIMA(1,1,0)(2,1,0)[12] : AIC=1019.239, Time=0.19 sec
ARIMA(1,1,0)(2,1,1)[12] : AIC=inf, Time=1.56 sec
ARIMA(1,1,0)(1,1,1)[12] : AIC=1020.493, Time=0.20 sec
ARIMA(0,1,0)(2,1,0)[12] : AIC=1032.120, Time=0.12 sec
ARIMA(2,1,0)(2,1,0)[12] : AIC=1021.120, Time=0.29 sec
ARIMA(1,1,1)(2,1,0)[12] : AIC=1021.032, Time=0.37 sec
ARIMA(0,1,1)(2,1,0)[12] : AIC=1019.178, Time=0.20 sec
ARIMA(0,1,1)(1,1,0)[12] : AIC=1020.425, Time=0.08 sec
ARIMA(0,1,1)(2,1,1)[12] : AIC=inf, Time=1.26 sec
ARIMA(0,1,1)(1,1,1)[12] : AIC=1020.327, Time=0.45 sec
ARIMA(0,1,2)(2,1,0)[12] : AIC=1021.148, Time=0.24 sec
ARIMA(1,1,2)(2,1,0)[12] : AIC=1022.805, Time=0.48 sec
ARIMA(0,1,1)(2,1,0)[12] intercept : AIC=1021.017, Time=0.49 sec
Best model: ARIMA(0,1,1)(2,1,0)[12]
Total fit time: 6.497 seconds
metrics = {'Passengers_pred': {'RMSE': 13.739551320848523, 'MAE': 13.497563987577488}}
| Passengers | month_no | Passengers_train | Passengers_test | Passengers_pred | Passengers_pred_error | Passengers_pred_lower | Passengers_pred_upper | |
|---|---|---|---|---|---|---|---|---|
| Month | ||||||||
| 1960-08-01 | 606 | 8 | 606.0 | NaN | NaN | NaN | NaN | NaN |
| 1960-09-01 | 508 | 9 | 508.0 | NaN | NaN | NaN | NaN | NaN |
| 1960-10-01 | 461 | 10 | NaN | 461.0 | 451.130222 | -9.869778 | 441.260444 | 441.260444 |
| 1960-11-01 | 390 | 11 | NaN | 390.0 | 405.185239 | 15.185239 | 420.370478 | 420.370478 |
| 1960-12-01 | 432 | 12 | NaN | 432.0 | 447.437675 | 15.437675 | 462.875350 | 462.875350 |
autoarima predict with exogvars
dfexogs = pd.DataFrame(data = {"month_no":[1,2,3,4,5]})
print("dfexogs")
display(dfexogs)
ts_period = pd.DateOffset(months=1)
df_pred=sf_autoarima.predict(Nperiods=3,dfexogs=dfexogs, ts_period=ts_period)
df_pred
dfexogs
| month_no | |
|---|---|
| 0 | 1 |
| 1 | 2 |
| 2 | 3 |
| 3 | 4 |
| 4 | 5 |
| Passengers_pred | |
|---|---|
| 1961-01-01 | 451.347077 |
| 1961-02-01 | 427.102222 |
| 1961-03-01 | 463.382490 |
2. SK Learn Models
Superstore Data
Often data needs pre-processing in the form of aggregattions and cleansing so that it is suitable for forecasting. The data for these examples is derived from the Superstore dataset avaliable here. In order to not over complicate this notebook we will not demonstrate all the pre-processing here. Howevver, for reference, all the details are contaned in the EDA/pre-procssing notebook - pre-processing notebook
Data pre-processing, prior to loading the data, includes the following steps
contiguous dates - ensure that there are no missing dates
the data is aggregated to sub category - the original dateset containes categories, sub-categories, and product ids. Below, we will further aggregate to category.
The output of the preprocesing (i.e., data loaded below) is avaialable in this github repo, pre-processed data.
After loading the data there are two additional steps (shown below) to prepare it for forecasting
The data will be aggregated to the three categories (office supplies, technology, furniture)
It will be transformed to wide format so that all categories are columns
All these transformations (before and after loading) typify transformations required in real situations.
Load data
df_sales = pd.read_csv(f'{datapath}/Superstore_subcatsales_2017_cdp.csv', parse_dates = ["Order Date"])
display(df_sales.head(10))
print(f'date min = {df_sales["Order Date"].min()}')
print(f'date max = {df_sales["Order Date"].max()}')
print(f'N rows (sales) = {df_sales.shape[0]}')
print( f'N Sub-Catetories = {df_sales.groupby("Sub-Category")["Sales"].count().count()} ')
| Order Date | Category | Sub-Category | Sales | Quantity | |
|---|---|---|---|---|---|
| 0 | 2014-01-03 | Office Supplies | Paper | 16.448 | 2.0 |
| 1 | 2014-01-04 | Office Supplies | Labels | 11.784 | 3.0 |
| 2 | 2014-01-04 | Office Supplies | Binders | 3.540 | 2.0 |
| 3 | 2014-01-04 | Office Supplies | Paper | 0.000 | 0.0 |
| 4 | 2014-01-04 | Office Supplies | Storage | 272.736 | 3.0 |
| 5 | 2014-01-05 | Office Supplies | Labels | 0.000 | 0.0 |
| 6 | 2014-01-05 | Office Supplies | Binders | 0.000 | 0.0 |
| 7 | 2014-01-05 | Office Supplies | Paper | 0.000 | 0.0 |
| 8 | 2014-01-05 | Office Supplies | Art | 19.536 | 3.0 |
| 9 | 2014-01-05 | Office Supplies | Storage | 0.000 | 0.0 |
date min = 2014-01-03 00:00:00
date max = 2017-12-30 00:00:00
N rows (sales) = 24431
N Sub-Catetories = 17
Aggregate to Category Time-Series
aggregate category sales by date
three categories - office supplies, furniture, technology
lineplots to observe the timeseries
aggs = {
"Sales":"sum",
"Quantity":"sum"
}
df_catsales = df_sales.groupby(["Order Date" , "Category"]).agg(aggs).reset_index()
df_catsales.head(10)
| Order Date | Category | Sales | Quantity | |
|---|---|---|---|---|
| 0 | 2014-01-03 | Office Supplies | 16.448 | 2.0 |
| 1 | 2014-01-04 | Office Supplies | 288.060 | 8.0 |
| 2 | 2014-01-05 | Office Supplies | 19.536 | 3.0 |
| 3 | 2014-01-06 | Furniture | 2573.820 | 9.0 |
| 4 | 2014-01-06 | Office Supplies | 685.340 | 15.0 |
| 5 | 2014-01-06 | Technology | 1147.940 | 6.0 |
| 6 | 2014-01-07 | Furniture | 76.728 | 3.0 |
| 7 | 2014-01-07 | Office Supplies | 10.430 | 7.0 |
| 8 | 2014-01-07 | Technology | 0.000 | 0.0 |
| 9 | 2014-01-08 | Furniture | 0.000 | 0.0 |
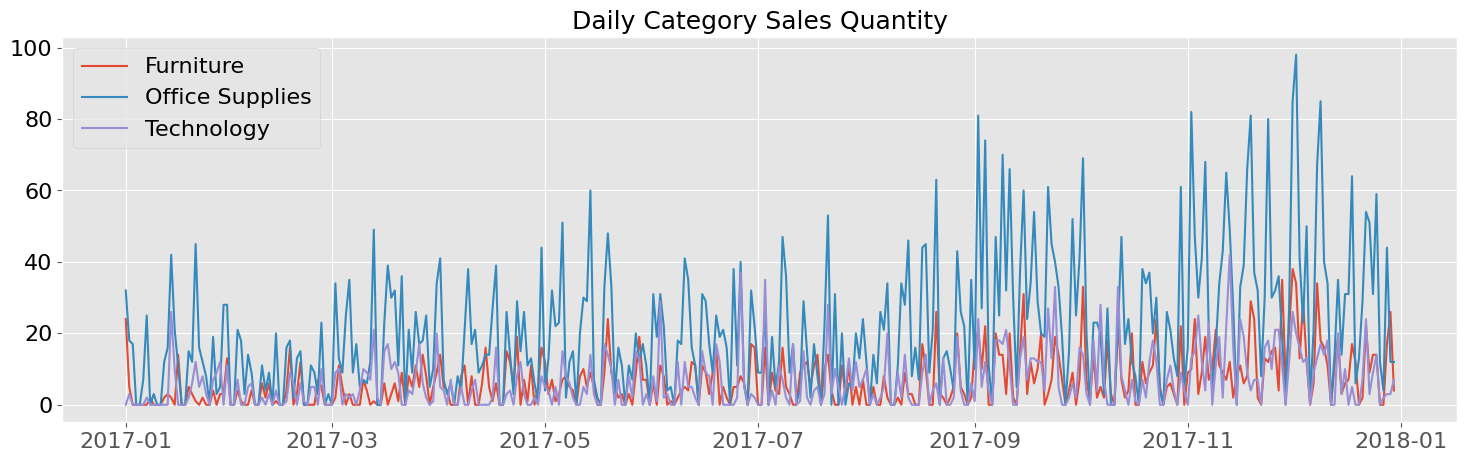
bp.lineplot(df_catsales,"Order Date","Quantity",hue="Category", y_axis_format = ",.0f" , title = "Daily Category Sales Quantity", figsize=(18,5))
d=datetime(2017,1,1)
bp.lineplot(df_catsales[df_catsales["Order Date"]>=d],"Order Date","Quantity",hue="Category", y_axis_format = ",.0f" ,
title = "Daily Category Sales Quantity", figsize=(18,5))
d=datetime(2017,9,1)
bp.lineplot(df_catsales[df_catsales["Order Date"]>=d],"Order Date","Quantity",hue="Category", y_axis_format = ",.0f" ,
title = "Daily Category Sales Quantity", figsize=(18,5))


Wide (Multivariate) Format
Below is a demonstration of how to pivot the DataFrame to a wide format
Wide format will be especially useful for accounting for exogenous variables and covariates.
Pivot to wide format - time (index or colum)
ll variables including co-variates in corresponding columns.
We are interested in forecasting unit sales volume, “Quantity.”
We do not need the sales revenue columns.
dfXYw = df_catsales.copy()
def to_flat_columns(hier_cols):
flat_cols=[]
for clist in hier_cols:
for n,ci in enumerate(clist):
c = ci if n == 0 else c+"_"+ci
flat_cols.append(c)
return flat_cols
dp = "Order Date" # demand period
# demand period (dp) = "Order Date" becomes the index
dfXYw = dfXYw.pivot(index=dp, columns = "Category" , values = ["Quantity" , "Sales"] )
flat_cols = to_flat_columns(dfXYw.columns)
dfXYw.columns = flat_cols
dfXYw = dfXYw.fillna(0)
display(dfXYw.head(3))
display(dfXYw.tail(7))
| Quantity_Furniture | Quantity_Office Supplies | Quantity_Technology | Sales_Furniture | Sales_Office Supplies | Sales_Technology | |
|---|---|---|---|---|---|---|
| Order Date | ||||||
| 2014-01-03 | 0.0 | 2.0 | 0.0 | 0.0 | 16.448 | 0.0 |
| 2014-01-04 | 0.0 | 8.0 | 0.0 | 0.0 | 288.060 | 0.0 |
| 2014-01-05 | 0.0 | 3.0 | 0.0 | 0.0 | 19.536 | 0.0 |
| Quantity_Furniture | Quantity_Office Supplies | Quantity_Technology | Sales_Furniture | Sales_Office Supplies | Sales_Technology | |
|---|---|---|---|---|---|---|
| Order Date | ||||||
| 2017-12-24 | 14.0 | 31.0 | 9.0 | 1393.4940 | 1479.638 | 3359.922 |
| 2017-12-25 | 14.0 | 59.0 | 14.0 | 832.4540 | 1465.265 | 401.208 |
| 2017-12-26 | 0.0 | 12.0 | 0.0 | 0.0000 | 814.594 | 0.000 |
| 2017-12-27 | 0.0 | 4.0 | 2.0 | 0.0000 | 13.248 | 164.388 |
| 2017-12-28 | 17.0 | 44.0 | 3.0 | 551.2568 | 1091.244 | 14.850 |
| 2017-12-29 | 26.0 | 12.0 | 3.0 | 2330.7180 | 282.440 | 302.376 |
| 2017-12-30 | 4.0 | 12.0 | 7.0 | 323.1360 | 299.724 | 90.930 |
Import XGBoost
from xgboost import XGBRegressor
Univariate fit and predict
Univariate forecast considers only one variable
Slideing forecast: 30 day sliding forecast, Ntest = 30 days
Predict horizon: Nhorizon = 1. The model is retrained after every Nhorizon time periods. Out-of-sample predictions are made to account for new observation after sliding over by 1 time period.
Target Variable: y = “Quantity_Furniture”
Lags: Nlags = 40. The univariate (y) will be lagged over 40 days.
ML model: In this case the model is an untrained XGBoost model. Generally, any SK Learn model can be input to sforecast
Output: DataFrame with output predictions, upper lower bounds, error wrt to target variable. Join the forecast result with the input DataFrame dfXY
Data scaling: By default the sliding model will scale the input variables with the SKlearn minmax scaler (normalization). However, sforecast offers the option to scale with the StandardScaler (standardization).
See the sforecast documentaton for more information.
dfXY = dfXYw[["Quantity_Furniture"]].copy()
print('dfXY')
display(dfXY.tail())
Ntest = 30
Nhorizon = 1
swin_params = {
"Ntest":Ntest,
"Nhorizon":Nhorizon,
"Nlags":40,
"minmax" :(0,None)}
y = ["Quantity_Furniture"]
xgb_model = XGBRegressor(n_estimators = 10, seed = 42, max_depth=5)
sfxgbuv = sf.sliding_forecast(y = y, swin_parameters=swin_params,model=xgb_model,model_type="sk")
df_pred_xgbuv = sfxgbuv.fit(dfXY)
print(f'\nmetrics = {sfxgbuv.metrics}')
dfXY_pred_xgbuv = dfXY.join(df_pred_xgbuv)
display(dfXY_pred_xgbuv)
dfXY
| Quantity_Furniture | |
|---|---|
| Order Date | |
| 2017-12-26 | 0.0 |
| 2017-12-27 | 0.0 |
| 2017-12-28 | 17.0 |
| 2017-12-29 | 26.0 |
| 2017-12-30 | 4.0 |
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
metrics = {'Quantity_Furniture_pred': {'RMSE': 11.551833881017961, 'MAE': 9.230052280426026}}
| Quantity_Furniture | Quantity_Furniture_train | Quantity_Furniture_test | Quantity_Furniture_pred | Quantity_Furniture_pred_error | Quantity_Furniture_pred_lower | Quantity_Furniture_pred_upper | |
|---|---|---|---|---|---|---|---|
| Order Date | |||||||
| 2014-01-03 | 0.0 | 0.0 | NaN | NaN | NaN | NaN | NaN |
| 2014-01-04 | 0.0 | 0.0 | NaN | NaN | NaN | NaN | NaN |
| 2014-01-05 | 0.0 | 0.0 | NaN | NaN | NaN | NaN | NaN |
| 2014-01-06 | 9.0 | 9.0 | NaN | NaN | NaN | NaN | NaN |
| 2014-01-07 | 3.0 | 3.0 | NaN | NaN | NaN | NaN | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 2017-12-26 | 0.0 | NaN | 0.0 | 12.570740 | 12.570740 | 0.0 | 20.869277 |
| 2017-12-27 | 0.0 | NaN | 0.0 | 4.480949 | 4.480949 | 0.0 | 12.779486 |
| 2017-12-28 | 17.0 | NaN | 17.0 | 13.771085 | -3.228915 | 0.0 | 22.069622 |
| 2017-12-29 | 26.0 | NaN | 26.0 | 3.977324 | -22.022676 | 0.0 | 12.275861 |
| 2017-12-30 | 4.0 | NaN | 4.0 | 7.670487 | 3.670487 | 0.0 | 15.969024 |
1458 rows × 7 columns
y = "Quantity_Furniture"
ytrain = y+"_train"
ytest = y+"_test"
ypred = y+"_pred"
error = y+"_pred_error"
dfxgbuv = dfXY_pred_xgbuv.reset_index().copy() # seaborn lineplot function needs x-axis to be a column
d=datetime(2017,9,1)
bp.lineplot(dfxgbuv[dfxgbuv["Order Date"]>=d], x= "Order Date", y=[ytrain, ytest , ypred] , figsize=(18,8) , legend=True)
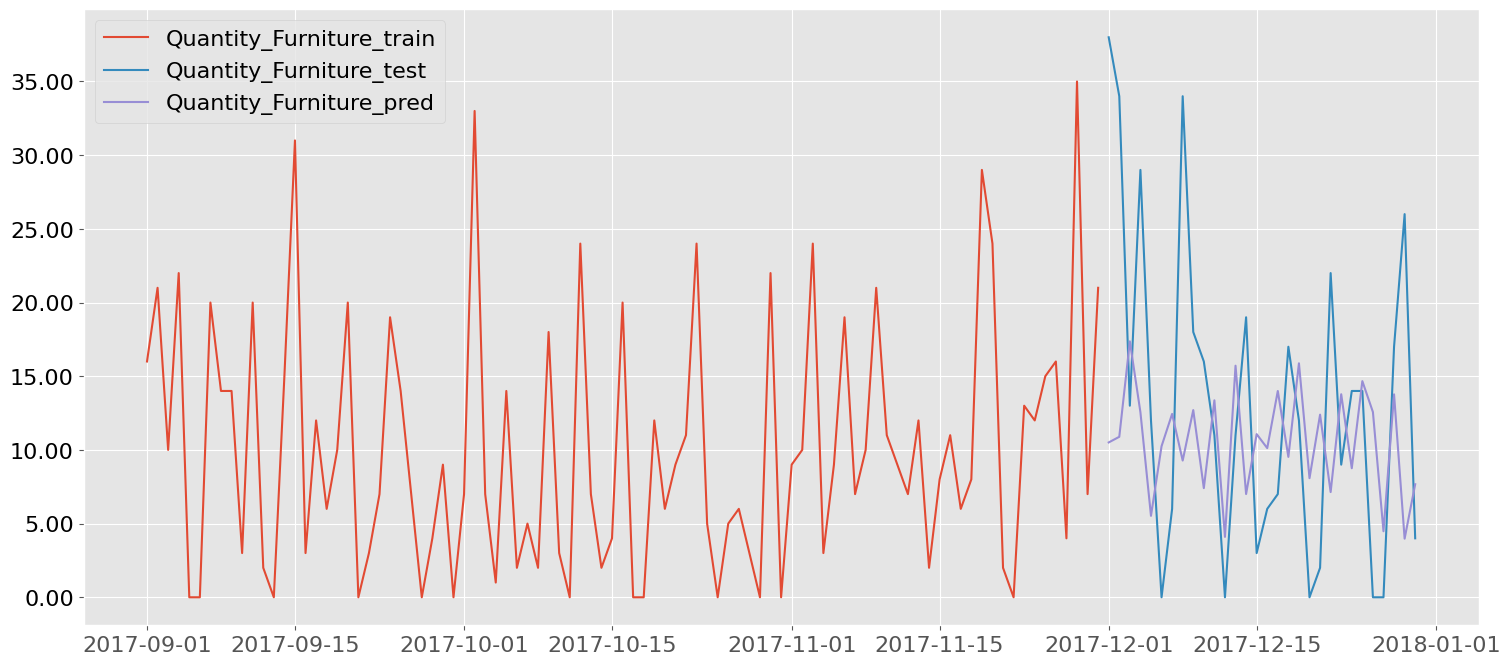
Predict XGB univariate
ts_period = pd.DateOffset(days=1)
df_pred=sfxgbuv.predict(Nperiods=2,ts_period=ts_period)
df_pred
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
| Quantity_Furniture_pred | |
|---|---|
| 2017-12-31 | 11.969523 |
| 2018-01-01 | 6.577347 |
Multivariate,Exogenous, Endogenous, Multiple Outputs, Nhorizon > 1
This case is again very similar to the previous examples
We inclue the co-variate variables and forecast co-variates
In this case, sforecast loops through the variables
Note, for more advanced types of models, such as deep-learning models, the multivarites forecasts can be generated simultaneously
Endogenous derived dependent attributes
dfXYw[["Quantity_Furniture", "Quantity_Office Supplies", "Quantity_Technology"]].copy()
| Quantity_Furniture | Quantity_Office Supplies | Quantity_Technology | |
|---|---|---|---|
| Order Date | |||
| 2014-01-03 | 0.0 | 2.0 | 0.0 |
| 2014-01-04 | 0.0 | 8.0 | 0.0 |
| 2014-01-05 | 0.0 | 3.0 | 0.0 |
| 2014-01-06 | 9.0 | 15.0 | 6.0 |
| 2014-01-07 | 3.0 | 7.0 | 0.0 |
| ... | ... | ... | ... |
| 2017-12-26 | 0.0 | 12.0 | 0.0 |
| 2017-12-27 | 0.0 | 4.0 | 2.0 |
| 2017-12-28 | 17.0 | 44.0 | 3.0 |
| 2017-12-29 | 26.0 | 12.0 | 3.0 |
| 2017-12-30 | 4.0 | 12.0 | 7.0 |
1458 rows × 3 columns
# transform dict
# -- transform can be one transform (str) or list
Nrw = 3 # rolling window widith
variable_transform_dict = {
"Quantity_Furniture":["mean","std"],
"Quantity_Office Supplies": ["mean","std"],
"Quantity_Technology": ["mean","std"]
}
derived_variables_transformer = sf.rolling_transformer(variable_transform_dict, Nrw=Nrw)
#---- test -----#
derived_attributes = derived_variables_transformer.get_derived_attribute_names()
Nendogs = len(derived_attributes)
print(f'Nendogs = {Nendogs}')
print()
print(f'derived_attriburtes = {derived_attributes}')
Nendogs = 6
derived_attriburtes = ['Quantity_Furniture_m1_mean3', 'Quantity_Furniture_m1_std3', 'Quantity_Office Supplies_m1_mean3', 'Quantity_Office Supplies_m1_std3', 'Quantity_Technology_m1_mean3', 'Quantity_Technology_m1_std3']
dfXY = dfXYw[["Quantity_Furniture", "Quantity_Office Supplies", "Quantity_Technology"]].copy()
# Exogenous Variables
dfXY["dayofweek"] = dfXY.index.dayofweek
display(dfXY.tail())
y = [ "Quantity_Furniture", "Quantity_Office Supplies", "Quantity_Technology"]
Ntest= 30
Nhorizon = 5
# sliding forecast inputs
swin_params = {
"Ntest":Ntest,
"Nhorizon":Nhorizon,
"Nlags":40,
"minmax" :(0,None),
"covars":[ "Quantity_Furniture", "Quantity_Office Supplies", "Quantity_Technology"],
"exogvars":"dayofweek",
"derived_attributes_transform":derived_variables_transformer # Endogenous Variables
}
xgb_model = XGBRegressor(n_estimators = 10, seed = 42, max_depth=5)
# sliding forecast model and forecast
sfxgbmv = sf.sliding_forecast(y = y, swin_parameters=swin_params,model=xgb_model,model_type="sk")
df_pred_xgbmv = sfxgbmv.fit(dfXY)
print(f'\nmetrics = {sfxgbmv.metrics}')
dfXY_pred_xgbmv = dfXY.join(df_pred_xgbmv)
display(dfXY_pred_xgbmv)
| Quantity_Furniture | Quantity_Office Supplies | Quantity_Technology | dayofweek | |
|---|---|---|---|---|
| Order Date | ||||
| 2017-12-26 | 0.0 | 12.0 | 0.0 | 1 |
| 2017-12-27 | 0.0 | 4.0 | 2.0 | 2 |
| 2017-12-28 | 17.0 | 44.0 | 3.0 | 3 |
| 2017-12-29 | 26.0 | 12.0 | 3.0 | 4 |
| 2017-12-30 | 4.0 | 12.0 | 7.0 | 5 |
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:618: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY_train[derived_attributes]=dfX_train[derived_attributes].values # put derived attributes id dfXY for consistency
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:618: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY_train[derived_attributes]=dfX_train[derived_attributes].values # put derived attributes id dfXY for consistency
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:618: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY_train[derived_attributes]=dfX_train[derived_attributes].values # put derived attributes id dfXY for consistency
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:618: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY_train[derived_attributes]=dfX_train[derived_attributes].values # put derived attributes id dfXY for consistency
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:618: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY_train[derived_attributes]=dfX_train[derived_attributes].values # put derived attributes id dfXY for consistency
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:618: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY_train[derived_attributes]=dfX_train[derived_attributes].values # put derived attributes id dfXY for consistency
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:618: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY_train[derived_attributes]=dfX_train[derived_attributes].values # put derived attributes id dfXY for consistency
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:618: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY_train[derived_attributes]=dfX_train[derived_attributes].values # put derived attributes id dfXY for consistency
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:618: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY_train[derived_attributes]=dfX_train[derived_attributes].values # put derived attributes id dfXY for consistency
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:618: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY_train[derived_attributes]=dfX_train[derived_attributes].values # put derived attributes id dfXY for consistency
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:618: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY_train[derived_attributes]=dfX_train[derived_attributes].values # put derived attributes id dfXY for consistency
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:618: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY_train[derived_attributes]=dfX_train[derived_attributes].values # put derived attributes id dfXY for consistency
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:618: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY_train[derived_attributes]=dfX_train[derived_attributes].values # put derived attributes id dfXY for consistency
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:618: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY_train[derived_attributes]=dfX_train[derived_attributes].values # put derived attributes id dfXY for consistency
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:618: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY_train[derived_attributes]=dfX_train[derived_attributes].values # put derived attributes id dfXY for consistency
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:618: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY_train[derived_attributes]=dfX_train[derived_attributes].values # put derived attributes id dfXY for consistency
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:618: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY_train[derived_attributes]=dfX_train[derived_attributes].values # put derived attributes id dfXY for consistency
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:618: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY_train[derived_attributes]=dfX_train[derived_attributes].values # put derived attributes id dfXY for consistency
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:618: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY_train[derived_attributes]=dfX_train[derived_attributes].values # put derived attributes id dfXY for consistency
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:618: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY_train[derived_attributes]=dfX_train[derived_attributes].values # put derived attributes id dfXY for consistency
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:618: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY_train[derived_attributes]=dfX_train[derived_attributes].values # put derived attributes id dfXY for consistency
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:618: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY_train[derived_attributes]=dfX_train[derived_attributes].values # put derived attributes id dfXY for consistency
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:618: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY_train[derived_attributes]=dfX_train[derived_attributes].values # put derived attributes id dfXY for consistency
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:618: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY_train[derived_attributes]=dfX_train[derived_attributes].values # put derived attributes id dfXY for consistency
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:618: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY_train[derived_attributes]=dfX_train[derived_attributes].values # put derived attributes id dfXY for consistency
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:618: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY_train[derived_attributes]=dfX_train[derived_attributes].values # put derived attributes id dfXY for consistency
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:618: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY_train[derived_attributes]=dfX_train[derived_attributes].values # put derived attributes id dfXY for consistency
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:618: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY_train[derived_attributes]=dfX_train[derived_attributes].values # put derived attributes id dfXY for consistency
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:618: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY_train[derived_attributes]=dfX_train[derived_attributes].values # put derived attributes id dfXY for consistency
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:618: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY_train[derived_attributes]=dfX_train[derived_attributes].values # put derived attributes id dfXY for consistency
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:618: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY_train[derived_attributes]=dfX_train[derived_attributes].values # put derived attributes id dfXY for consistency
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:618: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY_train[derived_attributes]=dfX_train[derived_attributes].values # put derived attributes id dfXY for consistency
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:618: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY_train[derived_attributes]=dfX_train[derived_attributes].values # put derived attributes id dfXY for consistency
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:618: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY_train[derived_attributes]=dfX_train[derived_attributes].values # put derived attributes id dfXY for consistency
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:618: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY_train[derived_attributes]=dfX_train[derived_attributes].values # put derived attributes id dfXY for consistency
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:618: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY_train[derived_attributes]=dfX_train[derived_attributes].values # put derived attributes id dfXY for consistency
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:618: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY_train[derived_attributes]=dfX_train[derived_attributes].values # put derived attributes id dfXY for consistency
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:618: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY_train[derived_attributes]=dfX_train[derived_attributes].values # put derived attributes id dfXY for consistency
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:618: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY_train[derived_attributes]=dfX_train[derived_attributes].values # put derived attributes id dfXY for consistency
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:618: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY_train[derived_attributes]=dfX_train[derived_attributes].values # put derived attributes id dfXY for consistency
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:618: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY_train[derived_attributes]=dfX_train[derived_attributes].values # put derived attributes id dfXY for consistency
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:618: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY_train[derived_attributes]=dfX_train[derived_attributes].values # put derived attributes id dfXY for consistency
metrics = {'Quantity_Furniture_pred': {'RMSE': 10.237966397374693, 'MAE': 8.159046093622843}, 'Quantity_Office Supplies_pred': {'RMSE': 25.272740464815477, 'MAE': 19.122392813364666}, 'Quantity_Technology_pred': {'RMSE': 8.04430011216907, 'MAE': 6.758149558305741}}
| Quantity_Furniture | Quantity_Office Supplies | Quantity_Technology | dayofweek | Quantity_Furniture_train | Quantity_Furniture_test | Quantity_Furniture_pred | Quantity_Furniture_pred_error | Quantity_Furniture_pred_lower | Quantity_Furniture_pred_upper | ... | Quantity_Office Supplies_pred | Quantity_Office Supplies_pred_error | Quantity_Office Supplies_pred_lower | Quantity_Office Supplies_pred_upper | Quantity_Technology_train | Quantity_Technology_test | Quantity_Technology_pred | Quantity_Technology_pred_error | Quantity_Technology_pred_lower | Quantity_Technology_pred_upper | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Order Date | |||||||||||||||||||||
| 2014-01-03 | 0.0 | 2.0 | 0.0 | 4 | 0.0 | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | 0.0 | NaN | NaN | NaN | NaN | NaN |
| 2014-01-04 | 0.0 | 8.0 | 0.0 | 5 | 0.0 | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | 0.0 | NaN | NaN | NaN | NaN | NaN |
| 2014-01-05 | 0.0 | 3.0 | 0.0 | 6 | 0.0 | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | 0.0 | NaN | NaN | NaN | NaN | NaN |
| 2014-01-06 | 9.0 | 15.0 | 6.0 | 0 | 9.0 | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | 6.0 | NaN | NaN | NaN | NaN | NaN |
| 2014-01-07 | 3.0 | 7.0 | 0.0 | 1 | 3.0 | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | 0.0 | NaN | NaN | NaN | NaN | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2017-12-26 | 0.0 | 12.0 | 0.0 | 1 | NaN | 0.0 | 9.119610 | 9.119610 | 0.000000 | 19.766999 | ... | 12.326706 | 0.326706 | 0.000000 | 18.121150 | NaN | 0.0 | 3.842882 | 3.842882 | 0.000000 | 13.018852 |
| 2017-12-27 | 0.0 | 4.0 | 2.0 | 2 | NaN | 0.0 | 7.249815 | 7.249815 | 0.000000 | 17.821237 | ... | 5.972883 | 1.972883 | 0.000000 | 25.486921 | NaN | 2.0 | 5.939587 | 3.939587 | 0.000000 | 18.639607 |
| 2017-12-28 | 17.0 | 44.0 | 3.0 | 3 | NaN | 17.0 | 14.951090 | -2.048910 | 0.000000 | 14.157401 | ... | 33.685150 | -10.314850 | 0.000000 | 26.331535 | NaN | 3.0 | 9.177584 | 6.177584 | 5.746384 | 14.851728 |
| 2017-12-29 | 26.0 | 12.0 | 3.0 | 4 | NaN | 26.0 | 18.493752 | -7.506248 | 7.027976 | 16.130080 | ... | 29.081686 | 17.081686 | 6.498539 | 51.453004 | NaN | 3.0 | 8.015482 | 5.015482 | 0.000000 | 14.442760 |
| 2017-12-30 | 4.0 | 12.0 | 7.0 | 5 | NaN | 4.0 | 8.236428 | 4.236428 | 2.083191 | 19.664430 | ... | 47.288303 | 35.288303 | 10.098175 | 77.300817 | NaN | 7.0 | 11.029782 | 4.029782 | 5.243685 | 20.638454 |
1458 rows × 22 columns
plot the observations, predicted output, and test (observations during corresponding to the predictions)
illustrate the confidence interval around the predictions. Sforecast defaults to 80% confidence periods, however the desired confidence interval can be specified as an input parameter.
y = ["Quantity_Furniture", "Quantity_Office Supplies", "Quantity_Technology"]
ytrain = y[0]+"_train"
ytest = y[0]+"_test"
ypred = y[0]+"_pred"
error = y[0]+"_pred_error"
dfxgbmv = dfXY_pred_xgbmv.reset_index().copy() # seaborn lineplot function needs x-axis to be a column
yfillbetween = (y[0]+"_pred_lower",y[0]+"_pred_upper")
d=datetime(2017,9,1)
bp.lineplot(dfxgbmv[dfxgbmv["Order Date"]>=d], x= "Order Date", y=[ytrain, ytest , ypred] , yfb=yfillbetween, figsize=(18,8) , legend=True)
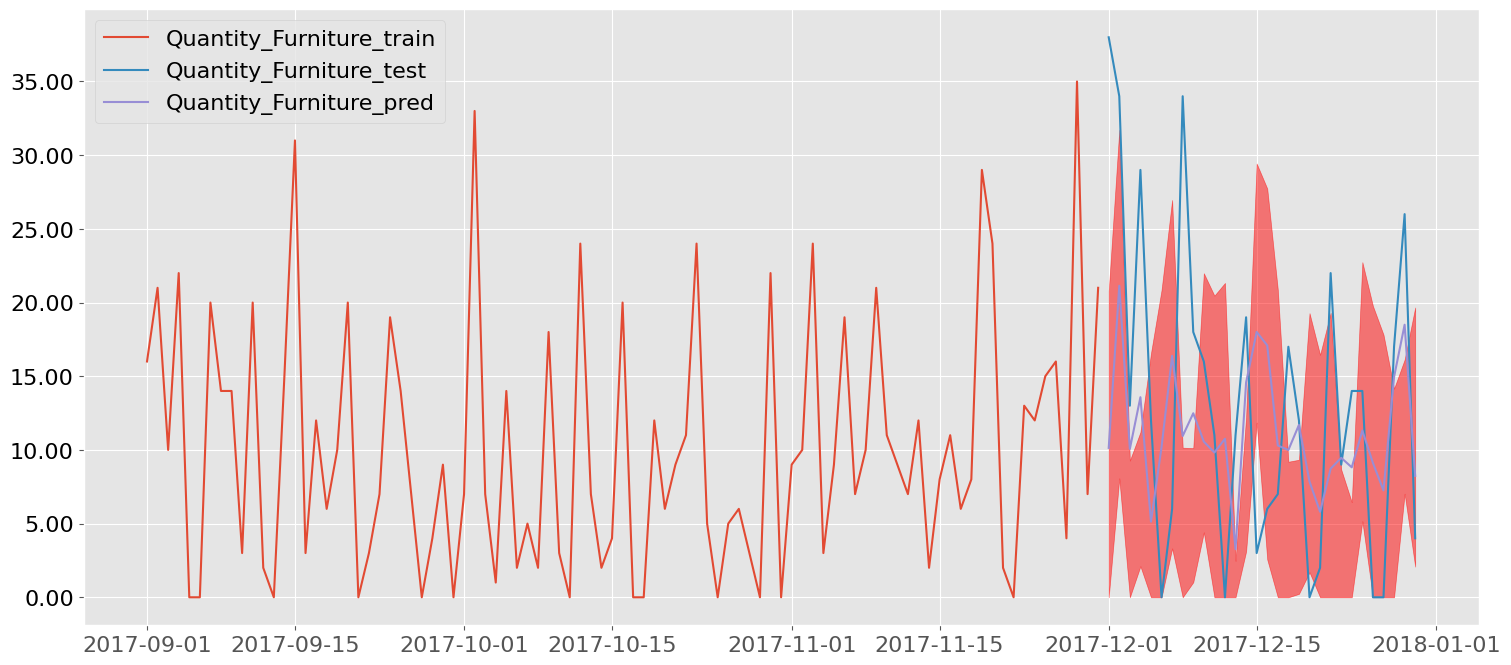
predict multi-output multivariat w/ exogenous and endogenous/derived variablese
ts_period = pd.DateOffset(days=1)
dfexogs=pd.DataFrame(data = {"dayofweek":[2,3,4,5,6]})
df_pred=sfxgbmv.predict(Nperiods=5,dfexogs = dfexogs, ts_period=ts_period)
df_pred
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:198: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
dfXY[cv_shift_vars] = dfXY[covars].shift(n)
| Quantity_Furniture_pred | Quantity_Office Supplies_pred | Quantity_Technology_pred | |
|---|---|---|---|
| 2017-12-31 | 10.260494 | 51.966106 | 15.558042 |
| 2018-01-01 | 9.077110 | 33.470715 | 11.326902 |
| 2018-01-02 | 7.369271 | 18.362717 | 3.324406 |
| 2018-01-03 | 2.566847 | 13.791990 | 7.186268 |
| 2018-01-04 | 11.101308 | 23.151442 | 9.975344 |
3. TensorFlow Models
TensorFlow Imports
from sklearn.preprocessing import LabelEncoder
M5 Sales data, 7 items, data transformation to wide format
M5 Sales 7 Items
df_m5sales7 = pd.read_csv("../data/m5_sales_7_items_events_cci_wide.csv", parse_dates = ["date"])
df_m5sales7 = df_m5sales7.set_index("date")
print("df_m5sales7")
display(df_m5sales7.tail())
# variable types
covars = [c for c in df_m5sales7.columns if "unit_sales_CA1_" in c]
catvars = [ "weekday", "event_name_1","event_name_2"]
exogvars = [ "year", "month" , "week", "snap_CA", "CCI_USA"]
Ncatvars = len(catvars)
Ncovars = len(covars)
Nexogvars = len(exogvars)
# dfXY ... covars + exogvars + catvars
cols = covars+catvars+exogvars
dfXY = df_m5sales7[cols].copy()
# label Encoding
le_catvars = [ "le_"+c for c in ["event_name_1","event_name_2"] ] # label encoded category columns ... weekday already encoded
print(le_catvars)
le = LabelEncoder()
dfXY[le_catvars] =dfXY[["event_name_1","event_name_2"] ].apply(le.fit_transform)
weekday_num = {"Sunday":0, "Monday":1, "Tuesday":2, "Wednesday":3, "Thursday":4, "Friday":5, "Saturday":6}
dfXY["le_weekday"] = dfXY["weekday"].apply( lambda x: weekday_num[x]) # create our own labels or label_encoder creates arbitrary number assignments
le_catvars = ["le_weekday"] + le_catvars # weekday is alread encoded ... add to le_catvars
print(f'le_catvars = {le_catvars}')
print(f'N event_name_1 labels = {dfXY.groupby("event_name_1")["event_name_1"].count().index.size}')
# embedding dimensions
eindim = [dfXY[le_catvars].groupby(c)[c].count().index.size + 1 for c in le_catvars] # add 1 to the dim or err in TF
eoutdim = [np.rint(np.log2(x)).astype(int) for x in eindim]
print(f'eindim = {eindim}')
print(f'eoutdim = {eoutdim}')
# display dfXY
print(f'dfXY.shape = {dfXY.shape}')
print(f'\ndfXY.head = ')
display(dfXY.head())
df_m5sales7
| unit_sales_CA1_HOUSEHOLD_416 | unit_sales_CA1_FOODS_044 | unit_sales_CA1_FOODS_030 | unit_sales_CA1_HOBBIES_418 | unit_sales_CA1_FOODS_185 | unit_sales_CA1_HOUSEHOLD_219 | unit_sales_CA1_FOODS_393 | sell_price_CA1_HOUSEHOLD_416 | sell_price_CA1_FOODS_044 | sell_price_CA1_FOODS_030 | ... | sell_price_CA1_FOODS_393 | year | month | week | weekday | yearmonth | event_name_1 | event_name_2 | snap_CA | CCI_USA | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| date | |||||||||||||||||||||
| 2016-05-18 | 2.0 | 0.0 | 7.0 | 1.0 | 4.0 | 0.0 | 5.0 | 3.88 | 2.5 | 1.48 | ... | 3.56 | 2016 | 5 | 20 | Wednesday | 201605 | NaN | NaN | 0 | 100.7612 |
| 2016-05-19 | 2.0 | 0.0 | 11.0 | 1.0 | 1.0 | 0.0 | 8.0 | 3.88 | 2.5 | 1.48 | ... | 3.56 | 2016 | 5 | 20 | Thursday | 201605 | NaN | NaN | 0 | 100.7612 |
| 2016-05-20 | 1.0 | 0.0 | 9.0 | 4.0 | 1.0 | 0.0 | 5.0 | 3.88 | 2.5 | 1.48 | ... | 3.56 | 2016 | 5 | 20 | Friday | 201605 | NaN | NaN | 0 | 100.7612 |
| 2016-05-21 | 0.0 | 3.0 | 9.0 | 0.0 | 2.0 | 2.0 | 5.0 | 3.88 | 2.5 | 1.48 | ... | 3.56 | 2016 | 5 | 20 | Saturday | 201605 | NaN | NaN | 0 | 100.7612 |
| 2016-05-22 | 3.0 | 2.0 | 8.0 | 0.0 | 2.0 | 1.0 | 15.0 | 3.88 | 2.5 | 1.48 | ... | 3.56 | 2016 | 5 | 20 | Sunday | 201605 | NaN | NaN | 0 | 100.7612 |
5 rows × 23 columns
['le_event_name_1', 'le_event_name_2']
le_catvars = ['le_weekday', 'le_event_name_1', 'le_event_name_2']
N event_name_1 labels = 30
eindim = [8, 32, 5]
eoutdim = [3, 5, 2]
dfXY.shape = (1206, 18)
dfXY.head =
| unit_sales_CA1_HOUSEHOLD_416 | unit_sales_CA1_FOODS_044 | unit_sales_CA1_FOODS_030 | unit_sales_CA1_HOBBIES_418 | unit_sales_CA1_FOODS_185 | unit_sales_CA1_HOUSEHOLD_219 | unit_sales_CA1_FOODS_393 | weekday | event_name_1 | event_name_2 | year | month | week | snap_CA | CCI_USA | le_event_name_1 | le_event_name_2 | le_weekday | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| date | ||||||||||||||||||
| 2013-02-02 | 2.0 | 0.0 | 43.0 | 0.0 | 0.0 | 0.0 | 4.0 | Saturday | NaN | NaN | 2013 | 2 | 5 | 1 | 98.72734 | 30 | 3 | 6 |
| 2013-02-03 | 0.0 | 0.0 | 33.0 | 0.0 | 0.0 | 0.0 | 5.0 | Sunday | SuperBowl | NaN | 2013 | 2 | 5 | 1 | 98.72734 | 26 | 3 | 0 |
| 2013-02-04 | 1.0 | 1.0 | 5.0 | 0.0 | 0.0 | 0.0 | 1.0 | Monday | NaN | NaN | 2013 | 2 | 6 | 1 | 98.72734 | 30 | 3 | 1 |
| 2013-02-05 | 0.0 | 1.0 | 14.0 | 0.0 | 0.0 | 0.0 | 2.0 | Tuesday | NaN | NaN | 2013 | 2 | 6 | 1 | 98.72734 | 30 | 3 | 2 |
| 2013-02-06 | 0.0 | 1.0 | 11.0 | 0.0 | 0.0 | 0.0 | 2.0 | Wednesday | NaN | NaN | 2013 | 2 | 6 | 1 | 98.72734 | 30 | 3 | 3 |
Univariate
Univariate Data
# y forecast variable
y = ["unit_sales_CA1_FOODS_030"]
# univariate data
print("dfXYtf univariate")
dfXYtf = dfXY[y]
display(dfXYtf.tail())
dfXYtf univariate
| unit_sales_CA1_FOODS_030 | |
|---|---|
| date | |
| 2016-05-18 | 7.0 |
| 2016-05-19 | 11.0 |
| 2016-05-20 | 9.0 |
| 2016-05-21 | 9.0 |
| 2016-05-22 | 8.0 |
TF Model - Dense Network, Univariate
Nlags=5
model_tf_dense = sf.get_dense_nn(Nlags)
Ndense = 5
Ndense = 20
Nout = 1
2024-07-27 08:25:53.957442: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 5)] 0
dense (Dense) (None, 20) 120
dropout (Dropout) (None, 20) 0
dense_1 (Dense) (None, 10) 210
dropout_1 (Dropout) (None, 10) 0
dense_2 (Dense) (None, 1) 11
=================================================================
Total params: 341
Trainable params: 341
Non-trainable params: 0
_________________________________________________________________
None
TF forecast Univariate
# display data
print("dfXYtf")
display(dfXYtf.tail())
# Model Initialization - WARNING
# ... recreate and compile the model ... reruning this cell will tune the existing model
# Forecast - fit
Ntest=10
Nhorizon = 1
swin_params = {
"Ntest":Ntest,
"Nhorizon":Nhorizon,
"Nlags":Nlags,
"minmax" :(0,None)
}
tf_params = {
"Nepochs_i": 500,
"Nepochs_t": 100,
"batch_size":100
}
sfuvtf = sf.sliding_forecast(y = y, model_type="tf", swin_parameters=swin_params,model=model_tf_dense, tf_parameters=tf_params)
df_pred_uv = sfuvtf.fit(dfXYtf)
print(f'\nmetrics = {sfuvtf.metrics}')
dfXY_pred_uvtf = dfXYtf.join(df_pred_uv)
display(dfXY_pred_uvtf.tail())
dfXYtf
| unit_sales_CA1_FOODS_030 | |
|---|---|
| date | |
| 2016-05-18 | 7.0 |
| 2016-05-19 | 11.0 |
| 2016-05-20 | 9.0 |
| 2016-05-21 | 9.0 |
| 2016-05-22 | 8.0 |
1/1 [==============================] - 0s 99ms/step
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
1/1 [==============================] - 0s 24ms/step
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
1/1 [==============================] - 0s 24ms/step
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
1/1 [==============================] - 0s 24ms/step
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
1/1 [==============================] - 0s 20ms/step
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
1/1 [==============================] - 0s 20ms/step
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
1/1 [==============================] - 0s 21ms/step
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
1/1 [==============================] - 0s 20ms/step
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
1/1 [==============================] - 0s 20ms/step
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
1/1 [==============================] - 0s 20ms/step
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
metrics = {'unit_sales_CA1_FOODS_030_pred': {'RMSE': 2.0170216323070433, 'MAE': 1.4662408351898193}}
| unit_sales_CA1_FOODS_030 | unit_sales_CA1_FOODS_030_train | unit_sales_CA1_FOODS_030_test | unit_sales_CA1_FOODS_030_pred | unit_sales_CA1_FOODS_030_pred_error | unit_sales_CA1_FOODS_030_pred_lower | unit_sales_CA1_FOODS_030_pred_upper | |
|---|---|---|---|---|---|---|---|
| date | |||||||
| 2016-05-18 | 7.0 | NaN | 7.0 | 6.827486 | -0.172514 | 2.882401 | 7.964314 |
| 2016-05-19 | 11.0 | NaN | 11.0 | 7.076028 | -3.923972 | 3.130944 | 8.212856 |
| 2016-05-20 | 9.0 | NaN | 9.0 | 8.534734 | -0.465266 | 4.589649 | 9.671562 |
| 2016-05-21 | 9.0 | NaN | 9.0 | 8.143085 | -0.856915 | 4.198001 | 9.279914 |
| 2016-05-22 | 8.0 | NaN | 8.0 | 8.126757 | 0.126757 | 4.181672 | 9.263585 |
df_loss_i = pd.DataFrame(data = { "epoch": range(len(sfuvtf.history_i.history["loss"])),
"loss":sfuvtf.history_i.history["loss"] })
bp.lineplot(df_loss_i, x ="epoch", y = "loss", figsize=(18,6) )
df_loss_t = pd.DataFrame(data = { "epoch": range(len(sfuvtf.history_t.history["loss"])),
"loss":sfuvtf.history_t.history["loss"] })
bp.lineplot(df_loss_t, x ="epoch", y = "loss", figsize=(18,6) )
y = "unit_sales_CA1_FOODS_030"
ytrain = y+"_train"
ytest = y+"_test"
ypred = y+"_pred"
error = y+"_pred_error"
df = dfXY_pred_uvtf.reset_index().copy() # seaborn lineplot function needs x-axis to be a column
error_avg =df[error].mean()
bp.lineplot(df, x="date", y=[ytrain, ytest , ypred], figsize=(18,4))
d=datetime(2016,1,1)
bp.lineplot(df[df["date"]>=d], x="date", y=[ytrain, ytest , ypred], figsize=(18,4))
bp.lineplot(df.tail(30), x="date", y=[ytest,ypred], figsize=(18,4), x_tick_rotation=80)
bp.lineplot(df.tail(30), x="date", y=error, h_line = [error_avg],
y_axis_format=".0f",linestyle="None", marker="o", color="k",
title = "errors over time", x_tick_rotation=80, figsize=(18,4))
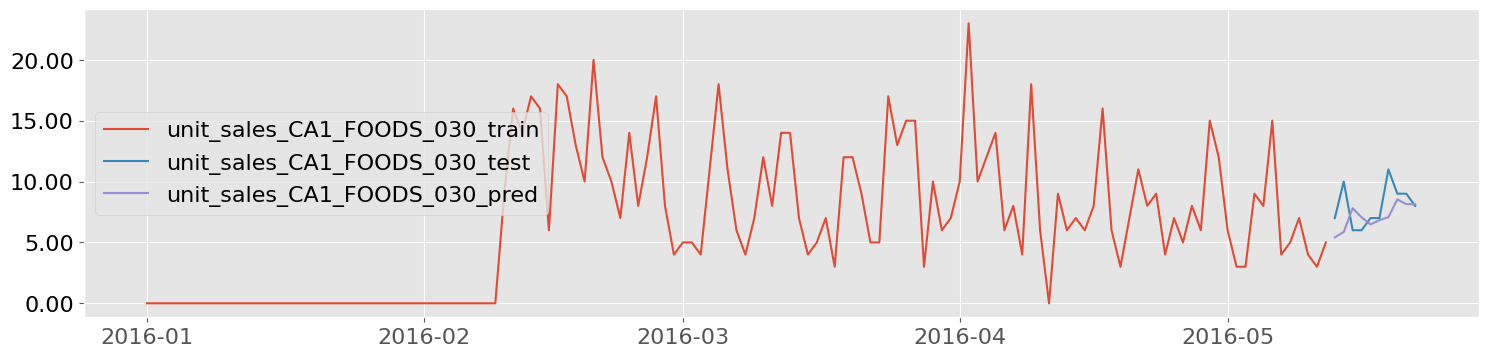
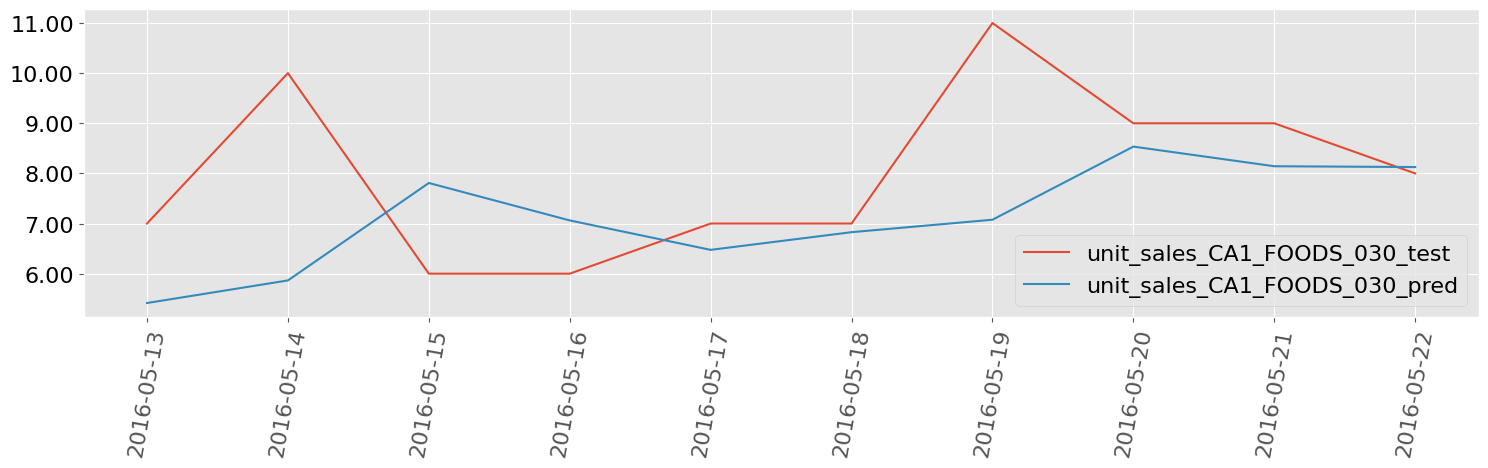

Predict TF Univariate
ts_period = pd.DateOffset(days=1)
#dfexogs=pd.DataFrame(data = {"dayofweek":[2,3,4,5,6]})
df_pred=sfuvtf.predict(Nperiods=3, ts_period=ts_period)
df_pred
1/1 [==============================] - 0s 23ms/step
1/1 [==============================] - 0s 22ms/step
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
1/1 [==============================] - 0s 22ms/step
| unit_sales_CA1_FOODS_030_pred | |
|---|---|
| 2016-05-23 | 7.764850 |
| 2016-05-24 | 7.687626 |
| 2016-05-25 | 7.475725 |
Multivariate (multiple output NN) with Exogenous, Endogenous, and Categorical
data
# same data as previous multivariate example
dfXYtf = dfXY[covars+exogvars+le_catvars].copy()
print(le_catvars)
print(exogvars)
print(dfXYtf.shape)
display(dfXYtf.tail())
['le_weekday', 'le_event_name_1', 'le_event_name_2']
['year', 'month', 'week', 'snap_CA', 'CCI_USA']
(1206, 15)
| unit_sales_CA1_HOUSEHOLD_416 | unit_sales_CA1_FOODS_044 | unit_sales_CA1_FOODS_030 | unit_sales_CA1_HOBBIES_418 | unit_sales_CA1_FOODS_185 | unit_sales_CA1_HOUSEHOLD_219 | unit_sales_CA1_FOODS_393 | year | month | week | snap_CA | CCI_USA | le_weekday | le_event_name_1 | le_event_name_2 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| date | |||||||||||||||
| 2016-05-18 | 2.0 | 0.0 | 7.0 | 1.0 | 4.0 | 0.0 | 5.0 | 2016 | 5 | 20 | 0 | 100.7612 | 3 | 30 | 3 |
| 2016-05-19 | 2.0 | 0.0 | 11.0 | 1.0 | 1.0 | 0.0 | 8.0 | 2016 | 5 | 20 | 0 | 100.7612 | 4 | 30 | 3 |
| 2016-05-20 | 1.0 | 0.0 | 9.0 | 4.0 | 1.0 | 0.0 | 5.0 | 2016 | 5 | 20 | 0 | 100.7612 | 5 | 30 | 3 |
| 2016-05-21 | 0.0 | 3.0 | 9.0 | 0.0 | 2.0 | 2.0 | 5.0 | 2016 | 5 | 20 | 0 | 100.7612 | 6 | 30 | 3 |
| 2016-05-22 | 3.0 | 2.0 | 8.0 | 0.0 | 2.0 | 1.0 | 15.0 | 2016 | 5 | 20 | 0 | 100.7612 | 0 | 30 | 3 |
Endogenous (derived) Attributes
# transform dict
# -- transform can be one transform (str) or list
Nrw = 3 # rolling window widith
variable_transform_dict = {
"unit_sales_CA1_FOODS_030" :["mean","std"],
"unit_sales_CA1_HOUSEHOLD_416": ["mean","std"],
"unit_sales_CA1_FOODS_393": ["mean","std"]
}
derived_variables_transformer = sf.rolling_transformer(variable_transform_dict, Nrw=Nrw)
derived_attributes = derived_variables_transformer.get_derived_attribute_names()
Nendogs = len(derived_attributes)
print(f'Nendogs = {Nendogs}')
print()
print(f'derived_attriburtes = {derived_attributes}')
Nendogs = 6
derived_attriburtes = ['unit_sales_CA1_FOODS_030_m1_mean3', 'unit_sales_CA1_FOODS_030_m1_std3', 'unit_sales_CA1_HOUSEHOLD_416_m1_mean3', 'unit_sales_CA1_HOUSEHOLD_416_m1_std3', 'unit_sales_CA1_FOODS_393_m1_mean3', 'unit_sales_CA1_FOODS_393_m1_std3']
NN Exogenous, Endogenous, Categorical MV
Nlags = 5
tf_model_dense_endog_exog_emb_mv = sf.get_dense_emb_nn(dfXYtf, Nlags, le_catvars, Ncovars= Ncovars, Nendogs = Nendogs, Nexogs = Nexogvars)
Ndin = 46
Ndense = 46
Nemb = 3
Nout = 7
cont_inputs = KerasTensor(type_spec=TensorSpec(shape=(None, 46), dtype=tf.float32, name='input_2'), name='input_2', description="created by layer 'input_2'")
cat_inputs_list = [<KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'input_3')>, <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'input_4')>, <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'input_5')>]
Model: "model_1"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_3 (InputLayer) [(None, 1)] 0 []
input_4 (InputLayer) [(None, 1)] 0 []
input_5 (InputLayer) [(None, 1)] 0 []
input_2 (InputLayer) [(None, 46)] 0 []
embedding (Embedding) (None, 1, 3) 24 ['input_3[0][0]']
embedding_1 (Embedding) (None, 1, 5) 160 ['input_4[0][0]']
embedding_2 (Embedding) (None, 1, 2) 10 ['input_5[0][0]']
dense_3 (Dense) (None, 46) 2162 ['input_2[0][0]']
flatten (Flatten) (None, 3) 0 ['embedding[0][0]']
flatten_1 (Flatten) (None, 5) 0 ['embedding_1[0][0]']
flatten_2 (Flatten) (None, 2) 0 ['embedding_2[0][0]']
concatenate (Concatenate) (None, 56) 0 ['dense_3[0][0]',
'flatten[0][0]',
'flatten_1[0][0]',
'flatten_2[0][0]']
dropout_2 (Dropout) (None, 56) 0 ['concatenate[0][0]']
dense_4 (Dense) (None, 56) 3192 ['dropout_2[0][0]']
dropout_3 (Dropout) (None, 56) 0 ['dense_4[0][0]']
dense_5 (Dense) (None, 28) 1596 ['dropout_3[0][0]']
dropout_4 (Dropout) (None, 28) 0 ['dense_5[0][0]']
dense_6 (Dense) (None, 7) 203 ['dropout_4[0][0]']
==================================================================================================
Total params: 7,347
Trainable params: 7,347
Non-trainable params: 0
__________________________________________________________________________________________________
None
# display data
y = ["unit_sales_CA1_FOODS_030", "unit_sales_CA1_HOUSEHOLD_416" , "unit_sales_CA1_FOODS_393" ]
print(f'\ny = {y}\n')
# forecast fit
Ntest = 10
Nhorizon = 1
swin_params = {
"Ntest":Ntest,
"Nhorizon":Nhorizon,
"Nlags": Nlags,
"minmax" :(0,None),
"covars":covars,
"exogvars":exogvars,
"catvars":le_catvars,
"derived_attributes_transform": derived_variables_transformer
}
tf_params = {
"Nepochs_i": 500,
"Nepochs_t": 200,
"batch_size":100
}
sfmvexen = sf.sliding_forecast(y = y, model_type="tf", swin_parameters=swin_params,model=tf_model_dense_endog_exog_emb_mv , tf_parameters=tf_params)
df_pred_mvexen = sfmvexen.fit(dfXYtf)
print(f'\nmetrics = {sfmvexen.metrics}')
dfXY_pred_mvexen = dfXY.join(df_pred_mvexen)
display(dfXY_pred_mvexen.tail())
y = ['unit_sales_CA1_FOODS_030', 'unit_sales_CA1_HOUSEHOLD_416', 'unit_sales_CA1_FOODS_393']
1/1 [==============================] - 0s 117ms/step
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
1/1 [==============================] - 0s 25ms/step
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
1/1 [==============================] - 0s 28ms/step
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
1/1 [==============================] - 0s 26ms/step
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
1/1 [==============================] - 0s 42ms/step
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
1/1 [==============================] - 0s 28ms/step
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
1/1 [==============================] - 0s 24ms/step
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
1/1 [==============================] - 0s 25ms/step
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
1/1 [==============================] - 0s 28ms/step
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
1/1 [==============================] - 0s 24ms/step
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
metrics = {'unit_sales_CA1_FOODS_030_pred': {'RMSE': 4.02866396005376, 'MAE': 3.551123094558716}, 'unit_sales_CA1_HOUSEHOLD_416_pred': {'RMSE': 1.2961768972721297, 'MAE': 1.1253128886222838}, 'unit_sales_CA1_FOODS_393_pred': {'RMSE': 3.933938322822191, 'MAE': 3.187389039993286}}
| unit_sales_CA1_HOUSEHOLD_416 | unit_sales_CA1_FOODS_044 | unit_sales_CA1_FOODS_030 | unit_sales_CA1_HOBBIES_418 | unit_sales_CA1_FOODS_185 | unit_sales_CA1_HOUSEHOLD_219 | unit_sales_CA1_FOODS_393 | weekday | event_name_1 | event_name_2 | ... | unit_sales_CA1_HOUSEHOLD_416_pred | unit_sales_CA1_HOUSEHOLD_416_pred_error | unit_sales_CA1_HOUSEHOLD_416_pred_lower | unit_sales_CA1_HOUSEHOLD_416_pred_upper | unit_sales_CA1_FOODS_393_train | unit_sales_CA1_FOODS_393_test | unit_sales_CA1_FOODS_393_pred | unit_sales_CA1_FOODS_393_pred_error | unit_sales_CA1_FOODS_393_pred_lower | unit_sales_CA1_FOODS_393_pred_upper | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| date | |||||||||||||||||||||
| 2016-05-18 | 2.0 | 0.0 | 7.0 | 1.0 | 4.0 | 0.0 | 5.0 | Wednesday | NaN | NaN | ... | 1.256720 | -0.743280 | 0.0 | 2.571532 | NaN | 5.0 | 4.173031 | -0.826969 | 0.000000 | 7.453100 |
| 2016-05-19 | 2.0 | 0.0 | 11.0 | 1.0 | 1.0 | 0.0 | 8.0 | Thursday | NaN | NaN | ... | 1.324675 | -0.675325 | 0.0 | 2.639487 | NaN | 8.0 | 4.242926 | -3.757074 | 0.000000 | 7.522995 |
| 2016-05-20 | 1.0 | 0.0 | 9.0 | 4.0 | 1.0 | 0.0 | 5.0 | Friday | NaN | NaN | ... | 1.041769 | 0.041769 | 0.0 | 2.356580 | NaN | 5.0 | 7.428666 | 2.428666 | 0.760713 | 10.708735 |
| 2016-05-21 | 0.0 | 3.0 | 9.0 | 0.0 | 2.0 | 2.0 | 5.0 | Saturday | NaN | NaN | ... | 1.286783 | 1.286783 | 0.0 | 2.601595 | NaN | 5.0 | 6.071188 | 1.071188 | 0.000000 | 9.351257 |
| 2016-05-22 | 3.0 | 2.0 | 8.0 | 0.0 | 2.0 | 1.0 | 15.0 | Sunday | NaN | NaN | ... | 1.512877 | -1.487123 | 0.0 | 2.827689 | NaN | 15.0 | 8.461512 | -6.538488 | 1.793558 | 11.741581 |
5 rows × 36 columns
Plot fit
df = dfXY_pred_mvexen.reset_index().copy() # seaborn lineplot function needs x-axis to be a column
y = "unit_sales_CA1_FOODS_030"
ytrain = y+"_train"
ytest = y+"_test"
ypred = y+"_pred"
bp.lineplot(df.tail(60), x="date", y=[ytrain, ytest,ypred], figsize=(18,4), x_tick_rotation=80)
y = "unit_sales_CA1_HOUSEHOLD_416"
ytrain = y+"_train"
ytest = y+"_test"
ypred = y+"_pred"
bp.lineplot(df.tail(60), x="date", y=[ytrain, ytest,ypred], figsize=(18,4), x_tick_rotation=80)
y = "unit_sales_CA1_FOODS_393"
ytrain = y+"_train"
ytest = y+"_test"
ypred = y+"_pred"
bp.lineplot(df.tail(60), x="date", y=[ytrain, ytest,ypred], figsize=(18,4), x_tick_rotation=80)
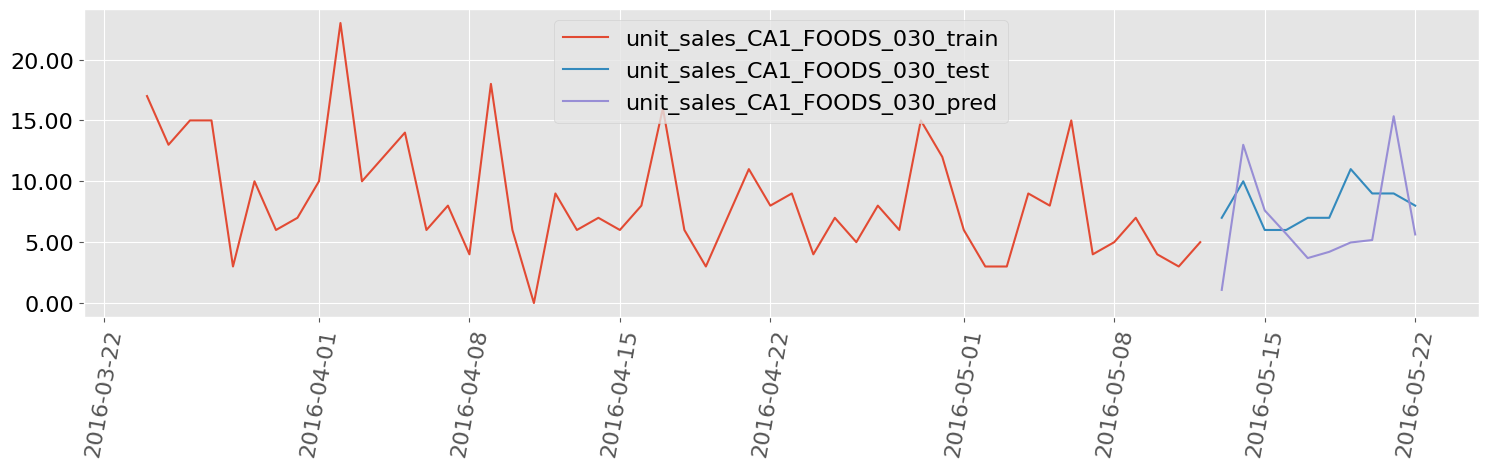
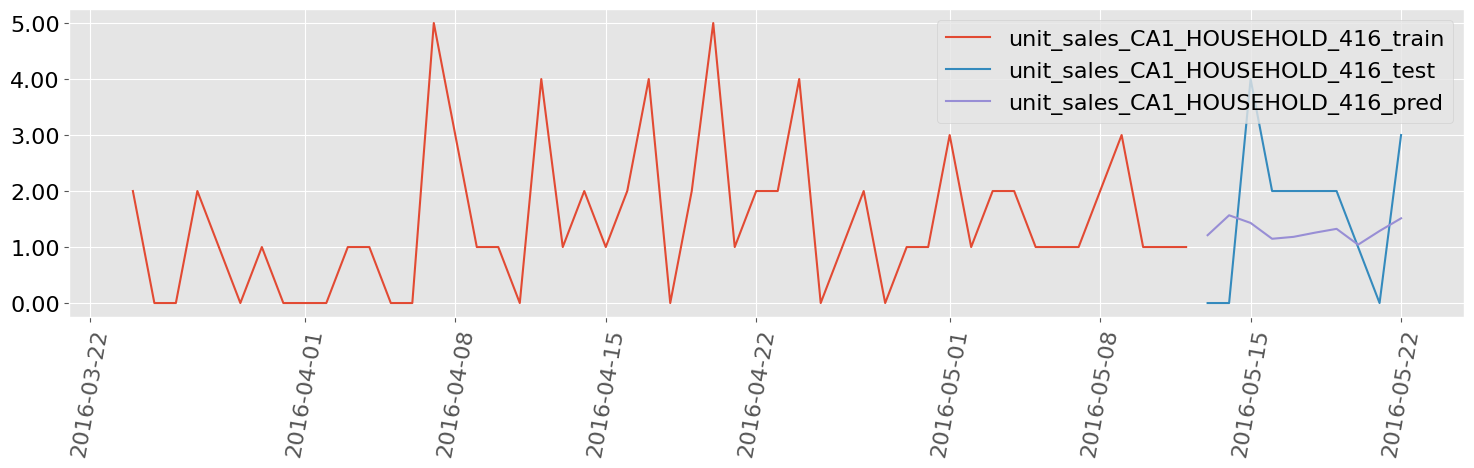
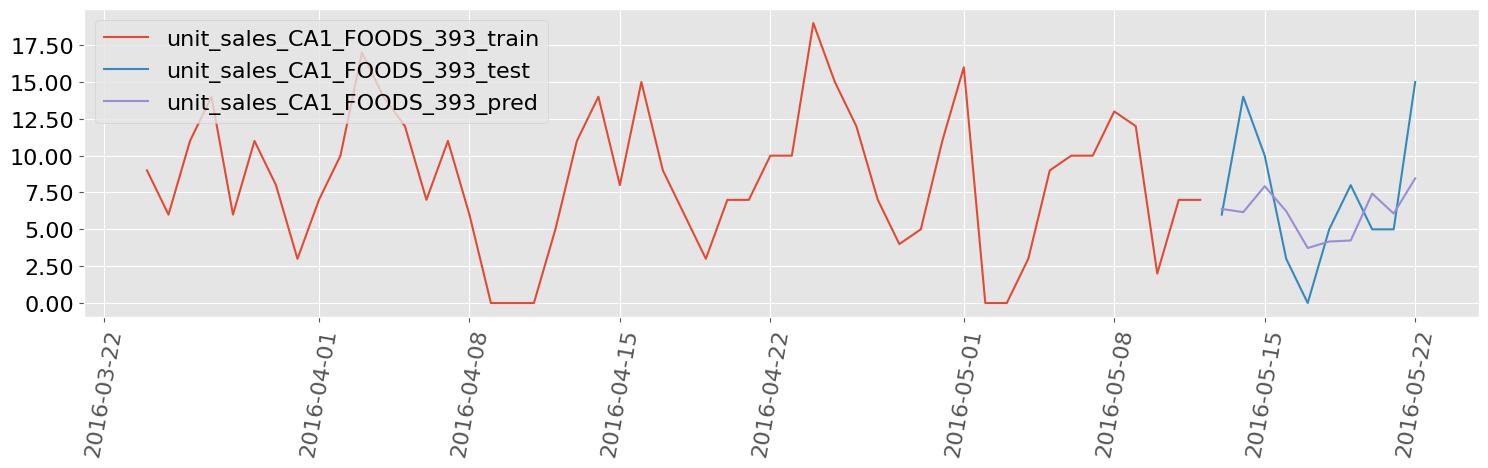
predict - exogenous, categorical, endogenous
ts_period = pd.DateOffset(days=1)
dfexogs=pd.DataFrame(data = {"year":5*[2016],
"month": 5*[5],
"week": 5*[21],
"snap_CA": 5*[0],
"CCI_USA":5*[100.7612]
})
dfcats=pd.DataFrame(data = {"le_weekday":[1,2,3,4,5], "le_event_name_1": 5*[30], "le_event_name_2": 5 *[3]})
df_pred=sfmvexen.predict(Nperiods=3,dfexogs = dfexogs, dfcats = dfcats, ts_period=ts_period)
df_pred
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
1/1 [==============================] - 0s 29ms/step
1/1 [==============================] - 0s 27ms/step
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:275: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.dfmemory[y].iloc[last_i] = yvalue
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
1/1 [==============================] - 0s 27ms/step
| unit_sales_CA1_FOODS_030_pred | unit_sales_CA1_HOUSEHOLD_416_pred | unit_sales_CA1_FOODS_393_pred | |
|---|---|---|---|
| 2016-05-23 | 6.481967 | 1.337323 | 8.977498 |
| 2016-05-24 | 7.812931 | 1.219274 | 6.063602 |
| 2016-05-25 | 1.010865 | 1.186116 | 4.074736 |
TF Exog Group Routed Directly to NN Output for Linear Combining
#### Data M5 7 items Week
file = "../data/M5_7items_week.csv"
sales_week_7_w = pd.read_csv(file, parse_dates = ["yearweek_dt"]).set_index("yearweek_dt")
### Prepare Data
y = ["unit_sales_FOODS_3_030"]
print(f'target variable = {y}')
# variable types
print("variable types ...")
covars = [c for c in sales_week_7_w.columns if "unit_sales_" in c]
catvars = [ "month", "event_name_1","event_name_2"]
exogvars = [ "yeariso" , "weekiso", "snap_CA", "CCI_USA", "sell_price_FOODS_3_030"]
exogs1 = [ "yeariso" , "weekiso", "snap_CA", "CCI_USA" ]
exogs2 = ["sell_price_FOODS_3_030"]
Ncatvars = len(catvars)
Ncovars = len(covars)
Nexogvars = len(exogvars)
exenvars = [exogs1, exogs2]
# dfXY ... covars + exogvars + catvars
cols = covars+catvars+exogvars
colsdp = cols #+ ["yearweek_dt"]
dfXYdp = sales_week_7_w[colsdp].copy()
dfXY = sales_week_7_w[cols].copy()
# label Encoding
le_catvars = [ "le_"+ c for c in catvars ] # label encoded category columns
le = LabelEncoder()
dfXY[le_catvars] = dfXY[catvars].apply(le.fit_transform)
# embedding dimensions
eindim = [dfXY[le_catvars].groupby(c)[c].count().index.size + 1 for c in le_catvars] # add 1 to the dim or err in TF
eoutdim = [np.rint(np.log2(x)).astype(int) for x in eindim]
dfXY = dfXY[covars+exogvars+le_catvars]
target variable = ['unit_sales_FOODS_3_030']
variable types ...
from keras.models import Model
from keras.layers import Input, Dense, Flatten, Embedding, concatenate, Dropout
import tensorflow as tf
### TensorFlow Model
Nlags = 5
Ndense1 = Nlags * Ncovars
Ndense2 = len(exogs1)
Nlinear = len(exogs2)
Nemb = Ncatvars
Nembout = sum(eoutdim)
Nout = Ncovars
#Ndense = Nlags # N continous/dense variables, in this case covars is 1 (univarate)
# Dense Network, 2 hidden layers, continuous variables ... covar lags and exogenous variables
covarlags_in = Input((Ndense1,))
hcovarlags = Dense(Ndense1, activation='relu')(covarlags_in)
exogs1_in = Input((Ndense2,))
hexogs1 = Dense(Ndense2, activation='relu')(exogs1_in)
exogs2_in = Input((Nlinear,))
hexogs2 = Dense(Nlinear)(exogs2_in)
# embeddings, cat vars
cat_inputs_list = [ Input((1,)) for c in range(Nemb) ] # one embedding for each categorical variable
emb_out_list = [Embedding(ein,eout,input_length=1)(cat) for ein,eout,cat in zip(eindim ,eoutdim,cat_inputs_list) ]
emb_flat_list = [Flatten()(emb_out) for emb_out in emb_out_list ]
# combined
combined = concatenate([hcovarlags]+emb_flat_list + [hexogs1] )
combined_d = Dropout(0.2)(combined)
# dense reduction layers
Nh1c = Ndense1 + Nembout + Ndense2 #
h1c = Dense(Nh1c, activation='relu')(combined_d)
h1c_d = Dropout(0.2)(h1c)
Nh2c = np.rint(Nh1c/2).astype(int)
h2c = Dense(Nh2c, activation='relu')(h1c_d)
h2c_d = Dropout(0.2)(h2c)
# combined to output ... combine the hidden reduced variables and the linear
combined_to_out = concatenate([h2c_d]+[hexogs2])
# output
output = Dense(Nout)(combined_to_out) # linear activation ... linear combination
model_tf_dense2_emb_so = Model(inputs=[covarlags_in, exogs1_in, exogs2_in, cat_inputs_list], outputs=output)
# define optimizer and compile
lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate=0.01,
decay_steps=10000,
decay_rate=0.9)
optimizer = tf.keras.optimizers.Adam(learning_rate=lr_schedule)
model_tf_dense2_emb_so.compile(loss='mse', optimizer=optimizer)
# Fit
Ntest = 3
swin_params = {
"Ntest":Ntest,
"Nhorizon":1,
"Nlags":Nlags,
"minmax" :(0,None),
"covars":covars,
"catvars":le_catvars,
"exogvars":exogvars,
"exenvars":exenvars
}
tf_params = {
"Nepochs_i": 500,
"Nepochs_t": 200,
"batch_size":100
}
sf_tf_dense_emb_so = sf.sliding_forecast(y = y, model_type="tf", swin_parameters=swin_params,model=model_tf_dense2_emb_so, tf_parameters=tf_params)
df_pred = sf_tf_dense_emb_so.fit(dfXY)
pred_expected = np.array([50.5, 46.3, 34.5 ])
y_pred = y[0]+"_pred"
pred_expected_p = pred_expected + 10
pred_expected_m = pred_expected - 10
pred_result = df_pred[y_pred].tail(Ntest).values
display(pred_result)
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
1/1 [==============================] - 0s 179ms/step
1/1 [==============================] - 0s 34ms/step
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
1/1 [==============================] - 0s 31ms/step
/Users/albertogutierrez/workspaces/sforecast/src/sforecast/sliding_forecast.py:245: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
df = pd.concat([df,dfnewrows])
array([57.09085846, 49.82725525, 24.96595955])
Conclusions and Summary
This notebook demonstrates the use of the Sforecast for fitting an ML model within a sliding/expanding window out-of-sample fit (test-train) and for making forward predictictions.
Sforecast supports classical forecast models, SK Learn based models, and TensorFlow models.
The examples demonstrate how to run univariate, and multivariate cases including single output (one forecast target), multiple output (multiple forecast targets), and also handling exogenous, endogenous, and categorical variables.
Sforecast significantly reduces the effort to manipulate data for all of these forecasting scenarios - lagged autoregressive co-variates, forecast horizons, and N-step forecasts.